JavaScript 数据结构与算法之美 - 十大经典排序算法汇总 #42
Assignees

Labels
Comments
This was referenced Jul 19, 2019
Closed
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
1. 前言
笔者写的 JavaScript 数据结构与算法之美 系列用的语言是 JavaScript ,旨在入门数据结构与算法和方便以后复习。
文中包含了
十大经典排序算法的思想、代码实现、一些例子、复杂度分析、动画、还有算法可视化工具。这应该是目前最全的
JavaScript 十大经典排序算法的讲解了吧。2. 如何分析一个排序算法
复杂度分析是整个算法学习的精髓。
时间和空间复杂度的详解,请看 JavaScript 数据结构与算法之美 - 时间和空间复杂度。
学习排序算法,我们除了学习它的算法原理、代码实现之外,更重要的是要学会如何评价、分析一个排序算法。
分析一个排序算法,要从
执行效率、内存消耗、稳定性三方面入手。2.1 执行效率
1. 最好情况、最坏情况、平均情况时间复杂度
我们在分析排序算法的时间复杂度时,要分别给出最好情况、最坏情况、平均情况下的时间复杂度。
除此之外,你还要说出最好、最坏时间复杂度对应的要排序的原始数据是什么样的。
2. 时间复杂度的系数、常数 、低阶
我们知道,时间复杂度反应的是数据规模 n 很大的时候的一个增长趋势,所以它表示的时候会忽略系数、常数、低阶。
但是实际的软件开发中,我们排序的可能是 10 个、100 个、1000 个这样规模很小的数据,所以,在对同一阶时间复杂度的排序算法性能对比的时候,我们就要把系数、常数、低阶也考虑进来。
3. 比较次数和交换(或移动)次数
这一节和下一节讲的都是基于比较的排序算法。基于比较的排序算法的执行过程,会涉及两种操作,一种是元素比较大小,另一种是元素交换或移动。
所以,如果我们在分析排序算法的执行效率的时候,应该把比较次数和交换(或移动)次数也考虑进去。
2.2 内存消耗
也就是看空间复杂度。
还需要知道如下术语:
2.3 稳定性
相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。比如: a 原本在 b 前面,而 a = b,排序之后,a 仍然在 b 的前面;
相等的元素,经过排序之后,相等元素之间原有的先后顺序改变。比如:a 原本在 b 的前面,而 a = b,排序之后, a 在 b 的后面;
3. 十大经典排序算法
3.1 冒泡排序(Bubble Sort)
思想
特点
实现
优化:当某次冒泡操作已经没有数据交换时,说明已经达到完全有序,不用再继续执行后续的冒泡操作。
测试
分析
冒泡的过程只涉及相邻数据的交换操作,只需要常量级的临时空间,所以它的空间复杂度为 O(1),是一个
原地排序算法。在冒泡排序中,只有交换才可以改变两个元素的前后顺序。
为了保证冒泡排序算法的稳定性,当有相邻的两个元素大小相等的时候,我们不做交换,相同大小的数据在排序前后不会改变顺序。
所以冒泡排序是
稳定的排序算法。最佳情况:T(n) = O(n),当数据已经是正序时。
最差情况:T(n) = O(n2),当数据是反序时。
平均情况:T(n) = O(n2)。
动画
3.2 插入排序(Insertion Sort)
插入排序又为分为 直接插入排序 和优化后的 拆半插入排序 与 希尔排序,我们通常说的插入排序是指直接插入排序。
一、直接插入
思想
一般人打扑克牌,整理牌的时候,都是按牌的大小(从小到大或者从大到小)整理牌的,那每摸一张新牌,就扫描自己的牌,把新牌插入到相应的位置。
插入排序的工作原理:通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
步骤
实现
测试
分析
插入排序算法的运行并不需要额外的存储空间,所以空间复杂度是 O(1),所以,这是一个
原地排序算法。在插入排序中,对于值相同的元素,我们可以选择将后面出现的元素,插入到前面出现元素的后面,这样就可以保持原有的前后顺序不变,所以插入排序是
稳定的排序算法。最佳情况:T(n) = O(n),当数据已经是正序时。
最差情况:T(n) = O(n2),当数据是反序时。
平均情况:T(n) = O(n2)。
动画
二、拆半插入
插入排序也有一种优化算法,叫做
拆半插入。思想
折半插入排序是直接插入排序的升级版,鉴于插入排序第一部分为已排好序的数组,我们不必按顺序依次寻找插入点,只需比较它们的中间值与待插入元素的大小即可。
步骤
测试
注意:和直接插入排序类似,折半插入排序每次交换的是相邻的且值为不同的元素,它并不会改变值相同的元素之间的顺序,因此它是稳定的。三、希尔排序
希尔排序是一个平均时间复杂度为 O(n log n) 的算法,会在下一个章节和 归并排序、快速排序、堆排序 一起讲,本文就不展开了。
3.3 选择排序(Selection Sort)
思路
选择排序算法的实现思路有点类似插入排序,也分已排序区间和未排序区间。但是选择排序每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾。
步骤
实现
测试
分析
选择排序空间复杂度为 O(1),是一种
原地排序算法。选择排序每次都要找剩余未排序元素中的最小值,并和前面的元素交换位置,这样破坏了稳定性。所以,选择排序是一种
不稳定的排序算法。无论是正序还是逆序,选择排序都会遍历 n2 / 2 次来排序,所以,最佳、最差和平均的复杂度是一样的。
最佳情况:T(n) = O(n2)。
最差情况:T(n) = O(n2)。
平均情况:T(n) = O(n2)。
动画
3.4 归并排序(Merge Sort)
思想
排序一个数组,我们先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。
归并排序采用的是
分治思想。分治,顾名思义,就是分而治之,将一个大问题分解成小的子问题来解决。小的子问题解决了,大问题也就解决了。
实现
测试
分析
第一,归并排序是原地排序算法吗 ?
这是因为归并排序的合并函数,在合并两个有序数组为一个有序数组时,需要借助额外的存储空间。
实际上,尽管每次合并操作都需要申请额外的内存空间,但在合并完成之后,临时开辟的内存空间就被释放掉了。在任意时刻,CPU 只会有一个函数在执行,也就只会有一个临时的内存空间在使用。临时内存空间最大也不会超过 n 个数据的大小,所以空间复杂度是 O(n)。
所以,归并排序
不是原地排序算法。第二,归并排序是稳定的排序算法吗 ?
merge 方法里面的 left[0] <= right[0] ,保证了值相同的元素,在合并前后的先后顺序不变。归并排序
是稳定的排序方法。第三,归并排序的时间复杂度是多少 ?
从效率上看,归并排序可算是排序算法中的
佼佼者。假设数组长度为 n,那么拆分数组共需 logn 步,又每步都是一个普通的合并子数组的过程,时间复杂度为 O(n),故其综合时间复杂度为 O(n log n)。最佳情况:T(n) = O(n log n)。
最差情况:T(n) = O(n log n)。
平均情况:T(n) = O(n log n)。
动画
3.5 快速排序 (Quick Sort)
快速排序的特点就是快,而且效率高!它是处理大数据最快的排序算法之一。
思想
特点:快速,常用。
缺点:需要另外声明两个数组,浪费了内存空间资源。
实现
方法一:
方法二:
测试
分析
第一,快速排序是原地排序算法吗 ?
因为 partition() 函数进行分区时,不需要很多额外的内存空间,所以快排是
原地排序算法。第二,快速排序是稳定的排序算法吗 ?
和选择排序相似,快速排序每次交换的元素都有可能不是相邻的,因此它有可能打破原来值为相同的元素之间的顺序。因此,快速排序并
不稳定。第三,快速排序的时间复杂度是多少 ?
极端的例子:如果数组中的数据原来已经是有序的了,比如 1,3,5,6,8。如果我们每次选择最后一个元素作为 pivot,那每次分区得到的两个区间都是不均等的。我们需要进行大约 n 次分区操作,才能完成快排的整个过程。每次分区我们平均要扫描大约 n / 2 个元素,这种情况下,快排的时间复杂度就从 O(nlogn) 退化成了 O(n2)。
最佳情况:T(n) = O(n log n)。
最差情况:T(n) = O(n2)。
平均情况:T(n) = O(n log n)。
动画
解答开篇问题
快排和归并用的都是分治思想,递推公式和递归代码也非常相似,那它们的区别在哪里呢 ?
可以发现:
由下而上的,先处理子问题,然后再合并。由上而下的,先分区,然后再处理子问题。3.6 希尔排序(Shell Sort)
思想
过程
实现
测试
分析
第一,希尔排序是原地排序算法吗 ?
希尔排序过程中,只涉及相邻数据的交换操作,只需要常量级的临时空间,空间复杂度为 O(1) 。所以,希尔排序是
原地排序算法。第二,希尔排序是稳定的排序算法吗 ?
我们知道,单次直接插入排序是稳定的,它不会改变相同元素之间的相对顺序,但在多次不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,可能导致相同元素相对顺序发生变化。
因此,希尔排序
不稳定。第三,希尔排序的时间复杂度是多少 ?
最佳情况:T(n) = O(n log n)。
最差情况:T(n) = O(n log2 n)。
平均情况:T(n) = O(n log2 n)。
动画
3.7 堆排序(Heap Sort)
堆的定义
堆其实是一种特殊的树。只要满足这两点,它就是一个堆。
完全二叉树:除了最后一层,其他层的节点个数都是满的,最后一层的节点都靠左排列。
也可以说:堆中每个节点的值都大于等于(或者小于等于)其左右子节点的值。这两种表述是等价的。
对于每个节点的值都
大于等于子树中每个节点值的堆,我们叫作大顶堆。对于每个节点的值都
小于等于子树中每个节点值的堆,我们叫作小顶堆。其中图 1 和 图 2 是大顶堆,图 3 是小顶堆,图 4 不是堆。除此之外,从图中还可以看出来,对于同一组数据,我们可以构建多种不同形态的堆。
思想
实现
测试
分析
第一,堆排序是原地排序算法吗 ?
整个堆排序的过程,都只需要极个别临时存储空间,所以堆排序
是原地排序算法。第二,堆排序是稳定的排序算法吗 ?
因为在排序的过程,存在将堆的最后一个节点跟堆顶节点互换的操作,所以就有可能改变值相同数据的原始相对顺序。
所以,堆排序是
不稳定的排序算法。第三,堆排序的时间复杂度是多少 ?
堆排序包括建堆和排序两个操作,建堆过程的时间复杂度是 O(n),排序过程的时间复杂度是 O(nlogn),所以,堆排序整体的时间复杂度是 O(nlogn)。
最佳情况:T(n) = O(n log n)。
最差情况:T(n) = O(n log n)。
平均情况:T(n) = O(n log n)。
动画
3.8 桶排序(Bucket Sort)
桶排序是计数排序的升级版,也采用了
分治思想。思想
比如:
桶排序利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。
为了使桶排序更加高效,我们需要做到这两点:
桶排序的核心:就在于怎么把元素平均分配到每个桶里,合理的分配将大大提高排序的效率。
实现
测试
分析
第一,桶排序是原地排序算法吗 ?
因为桶排序的空间复杂度,也即内存消耗为 O(n),所以
不是原地排序算法。第二,桶排序是稳定的排序算法吗 ?
取决于每个桶的排序方式,比如:快排就不稳定,归并就稳定。
第三,桶排序的时间复杂度是多少 ?
因为桶内部的排序可以有多种方法,是会对桶排序的时间复杂度产生很重大的影响。所以,桶排序的时间复杂度可以是多种情况的。
总的来说最佳情况:当输入的数据可以均匀的分配到每一个桶中。
最差情况:当输入的数据被分配到了同一个桶中。
以下是
桶的内部排序为快速排序的情况:如果要排序的数据有 n 个,我们把它们均匀地划分到 m 个桶内,每个桶里就有 k =n / m 个元素。每个桶内部使用快速排序,时间复杂度为 O(k * logk)。
m 个桶排序的时间复杂度就是 O(m * k * logk),因为 k = n / m,所以整个桶排序的时间复杂度就是 O(n*log(n/m))。
当桶的个数 m 接近数据个数 n 时,log(n/m) 就是一个非常小的常量,这个时候桶排序的时间复杂度接近 O(n)。
最佳情况:T(n) = O(n)。当输入的数据可以均匀的分配到每一个桶中。
最差情况:T(n) = O(nlogn)。当输入的数据被分配到了同一个桶中。
平均情况:T(n) = O(n)。
适用场景
动画
3.9 计数排序(Counting Sort)
思想
关键在于理解最后反向填充时的操作。
使用条件
实现
方法一:
测试
方法二:
测试
例子
可以认为,计数排序其实是桶排序的一种特殊情况。
当要排序的 n 个数据,所处的范围并不大的时候,比如最大值是 k,我们就可以把数据划分成 k 个桶。每个桶内的数据值都是相同的,省掉了桶内排序的时间。
我们都经历过高考,高考查分数系统你还记得吗?我们查分数的时候,系统会显示我们的成绩以及所在省的排名。如果你所在的省有 50 万考生,如何通过成绩快速排序得出名次呢?
分析
因为计数排序的空间复杂度为 O(k),k 桶的个数,所以不是原地排序算法。
计数排序不改变相同元素之间原本相对的顺序,因此它是稳定的排序算法。
最佳情况:T(n) = O(n + k)
最差情况:T(n) = O(n + k)
平均情况:T(n) = O(n + k)
k 是待排序列最大值。
动画
3.10 基数排序(Radix Sort)
思想
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。
例子
假设我们有 10 万个手机号码,希望将这 10 万个手机号码从小到大排序,你有什么比较快速的排序方法呢 ?
这个问题里有这样的规律:假设要比较两个手机号码 a,b 的大小,如果在前面几位中,a 手机号码已经比 b 手机号码大了,那后面的几位就不用看了。所以是基于
位来比较的。桶排序、计数排序能派上用场吗 ?手机号码有 11 位,范围太大,显然不适合用这两种排序算法。针对这个排序问题,有没有时间复杂度是 O(n) 的算法呢 ? 有,就是基数排序。
使用条件
位来比较;方案
按照优先从高位或低位来排序有两种实现方案:
实现
测试
分析
第一,基数排序是原地排序算法吗 ?
因为计数排序的空间复杂度为 O(n + k),所以不是原地排序算法。
第二,基数排序是稳定的排序算法吗 ?
基数排序不改变相同元素之间的相对顺序,因此它是稳定的排序算法。
第三,基数排序的时间复杂度是多少 ?
最佳情况:T(n) = O(n * k)
最差情况:T(n) = O(n * k)
平均情况:T(n) = O(n * k)
其中,k 是待排序列最大值。
动画
LSD 基数排序动图演示:
4. 复杂度对比
十大经典排序算法的 时间复杂度与空间复杂度 比较。
名词解释:
5. 算法可视化工具
算法可视化工具 algorithm-visualizer
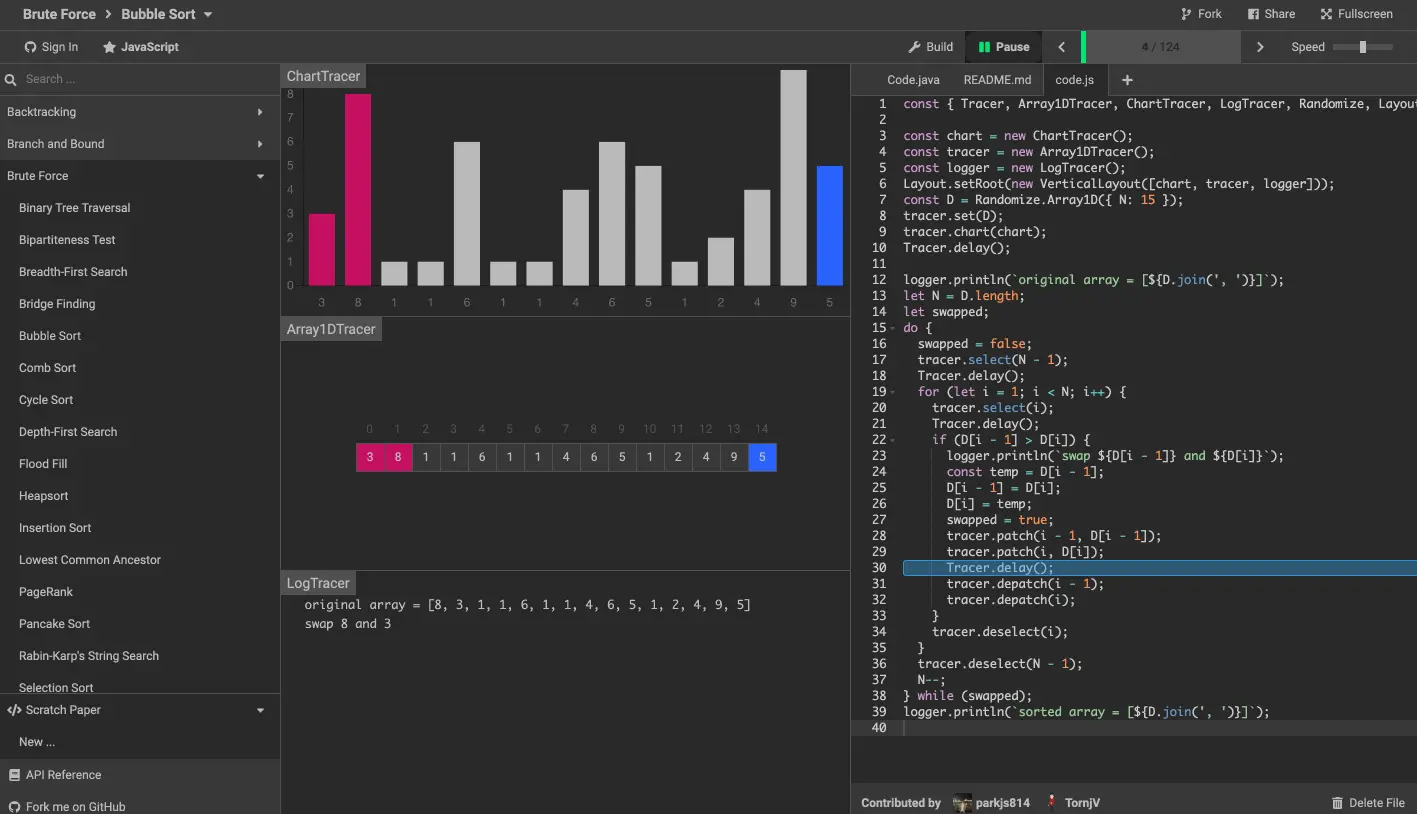
算法可视化工具 algorithm-visualizer 是一个交互式的在线平台,可以从代码中可视化算法,还可以看到代码执行的过程。旨在通过交互式可视化的执行来揭示算法背后的机制。
效果如下图:
算法可视化动画网站 https://visualgo.net/en
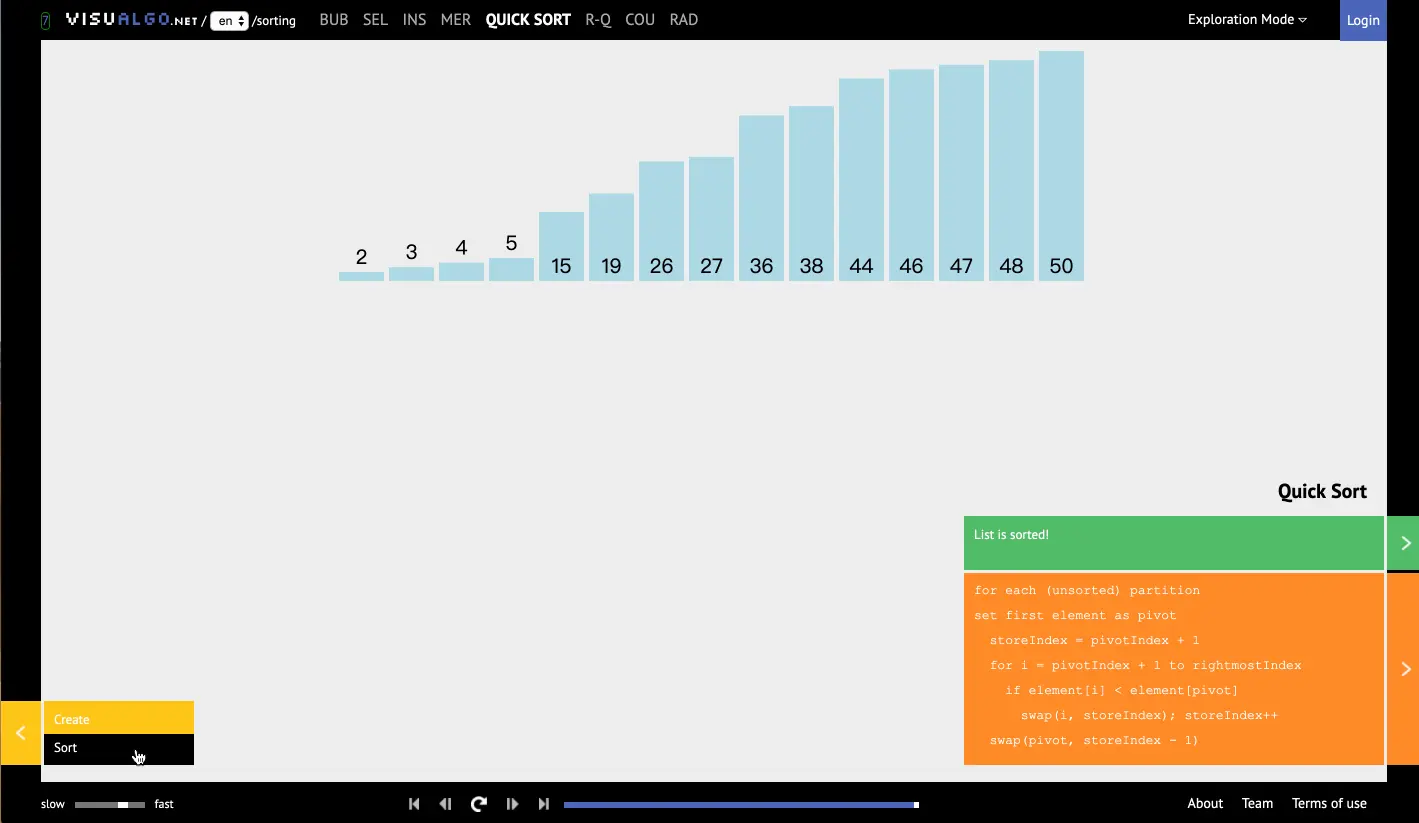
效果如下图:
算法可视化动画网站 www.ee.ryerson.ca
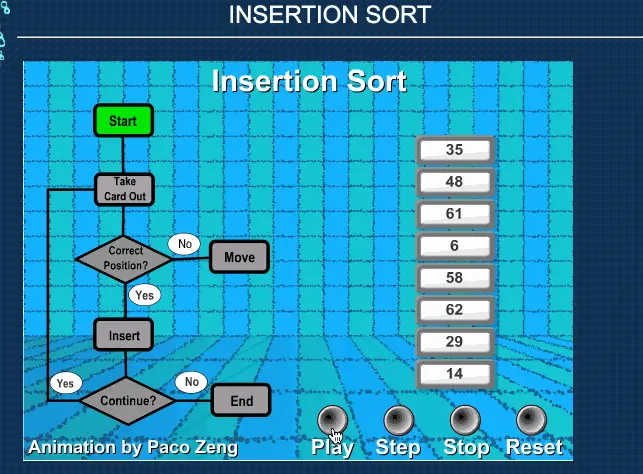
效果如下图:
illustrated-algorithms

变量和操作的可视化表示增强了控制流和实际源代码。您可以快速前进和后退执行,以密切观察算法的工作方式。
效果如下图:
6. 系列文章
JavaScript 数据结构与算法之美 系列文章,暂时写了如下的 11 篇文章,后续还有想写的内容,再补充。
所写的内容只是数据结构与算法内容的冰山一角,如果你还想学更多的内容,推荐学习王争老师的 数据结构与算法之美。
从时间和空间复杂度、基础数据结构到排序算法,文章的内容有一定的关联性,所以阅读时推荐按顺序来阅读,效果更佳。
7. 最后
文中所有的代码及测试事例都已经放到我的 GitHub 上了。
笔者为了写好这系列的文章,花费了大量的业余时间,边学边写,边写边修改,前后历时差不多 2 个月,入门级的文章总算是写完了。
如果你觉得有用或者喜欢,就点收藏,顺便点个赞吧,你的支持是我最大的鼓励 !
The text was updated successfully, but these errors were encountered: