[提问]Informer 中为什么需要引入 Resync 机制? #11
Comments
|
因为这些操作都是异步的 合理的sync可以提高事件消费的容错性 |
感谢回答~ 能举个例子说说什么情况下会出现事件消费异常吗? |
嗯 ... 作为一个分布式的系统 排除代码之外 网络,基础设施等都有可能导致消费的异常,resync是一个很常规的操作(简单来说比如你的mq消费失败你会怎么做) |
这里的消费者指的是从 FIFODelta 队列中取 event 的 workQueue 和从 workQueue 取 key 的 control loop 吗?在我看来虽然是异步的操作,但是这里面消费者和消息队列是同一个服务,好像不会有网络之类的消费异常问题 |
以前看过的一篇文章 https://www.kubernetes.org.cn/2693.html ,可能这篇文章比我在这码字回答的更有效,实际上你说的relist也是一种resync的做法 |
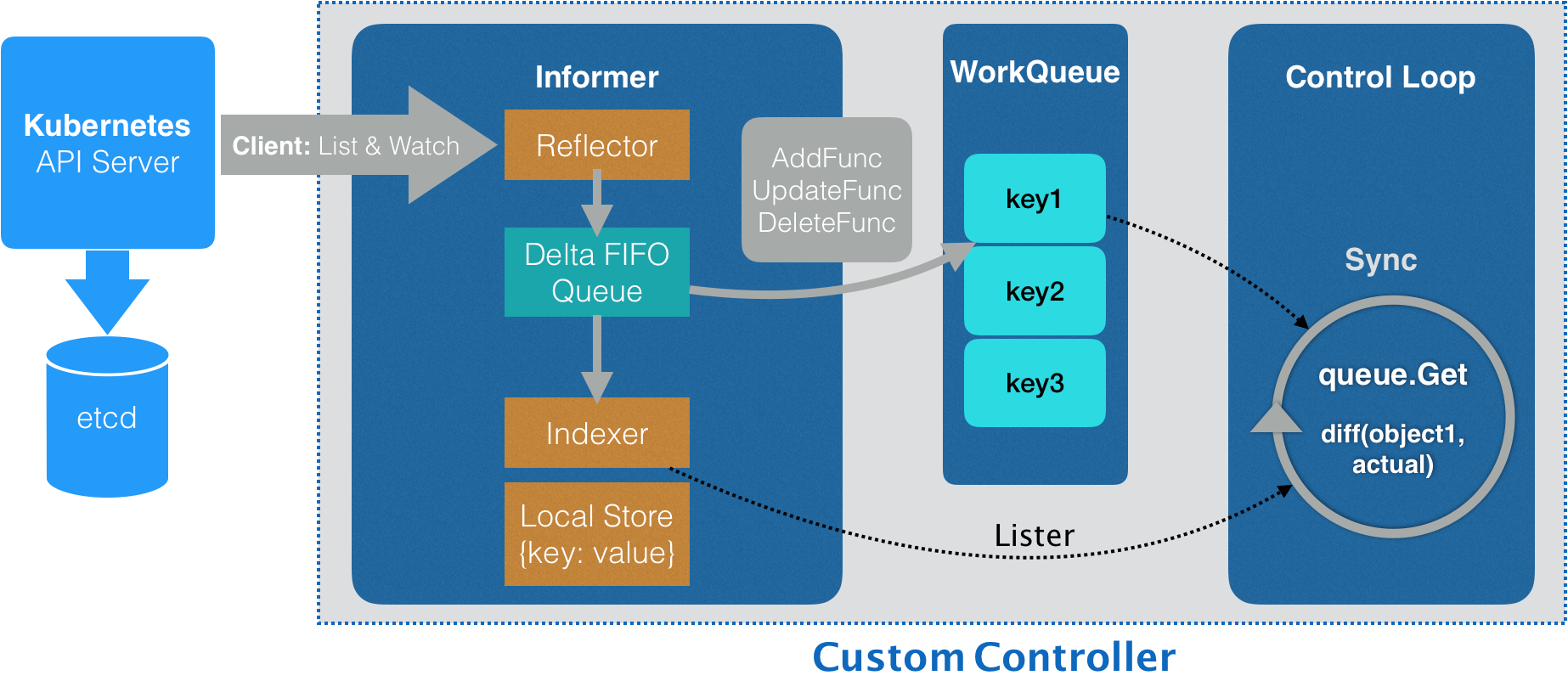
一、Client-go 中的 Informer 工作流程图
二、Resync 机制的引入我们在使用 SharedInformerFactory 去创建 SharedInformer 时,需要填一个 ResyncDuration 的参数 // k8s.io/client-go/informers/factory.go
// NewSharedInformerFactory constructs a new instance of sharedInformerFactory for all namespaces.
func NewSharedInformerFactory(client kubernetes.Interface, defaultResync time.Duration) SharedInformerFactory {
return NewSharedInformerFactoryWithOptions(client, defaultResync)
}这个参数指的是,多久从 Indexer 缓存中同步一次数据到 Delta FIFO 队列,重新走一遍流程 // k8s.io/client-go/tools/cache/delta_fifo.go
// 重新同步一次 Indexer 缓存数据到 Delta FIFO 队列中
func (f *DeltaFIFO) Resync() error {
f.lock.Lock()
defer f.lock.Unlock()
if f.knownObjects == nil {
return nil
}
// 遍历 indexer 中的 key,传入 syncKeyLocked 中处理
keys := f.knownObjects.ListKeys()
for _, k := range keys {
if err := f.syncKeyLocked(k); err != nil {
return err
}
}
return nil
}
func (f *DeltaFIFO) syncKeyLocked(key string) error {
obj, exists, err := f.knownObjects.GetByKey(key)
if err != nil {
klog.Errorf("Unexpected error %v during lookup of key %v, unable to queue object for sync", err, key)
return nil
} else if !exists {
klog.Infof("Key %v does not exist in known objects store, unable to queue object for sync", key)
return nil
}
// 如果发现 FIFO 队列中已经有相同 key 的 event 进来了,说明该资源对象有了新的 event,
// 在 Indexer 中旧的缓存应该失效,因此不做 Resync 处理直接返回 nil
id, err := f.KeyOf(obj)
if err != nil {
return KeyError{obj, err}
}
if len(f.items[id]) > 0 {
return nil
}
// 重新放入 FIFO 队列中
if err := f.queueActionLocked(Sync, obj); err != nil {
return fmt.Errorf("couldn't queue object: %v", err)
}
return nil
}为什么需要 Resync 机制呢?因为在处理 SharedInformer 事件回调时,可能存在处理失败的情况,定时的 Resync 让这些处理失败的事件有了重新 onUpdate 处理的机会。 // k8s.io/client-go/tools/cache/shared_informer.go
func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error {
s.blockDeltas.Lock()
defer s.blockDeltas.Unlock()
// from oldest to newest
for _, d := range obj.(Deltas) {
// 判断事件类型,看事件是通过新增、更新、替换、删除还是 Resync 重新同步产生的
switch d.Type {
case Sync, Replaced, Added, Updated:
s.cacheMutationDetector.AddObject(d.Object)
if old, exists, err := s.indexer.Get(d.Object); err == nil && exists {
if err := s.indexer.Update(d.Object); err != nil {
return err
}
isSync := false
switch {
case d.Type == Sync:
// 如果是通过 Resync 重新同步得到的事件则做个标记
isSync = true
case d.Type == Replaced:
...
}
// 如果是通过 Resync 重新同步得到的事件,则触发 onUpdate 回调
s.processor.distribute(updateNotification{oldObj: old, newObj: d.Object}, isSync)
} else {
if err := s.indexer.Add(d.Object); err != nil {
return err
}
s.processor.distribute(addNotification{newObj: d.Object}, false)
}
case Deleted:
if err := s.indexer.Delete(d.Object); err != nil {
return err
}
s.processor.distribute(deleteNotification{oldObj: d.Object}, false)
}
}
return nil
}从上面对 Delta FIFO 的队列处理源码可看出,如果是从 Resync 重新同步到 Delta FIFO 队列的事件,会分发到 updateNotification 中触发 onUpdate 的回调 三、总结Resync 机制的引入,定时将 Indexer 缓存事件重新同步到 Delta FIFO 队列中,在处理 SharedInformer 事件回调时,让处理失败的事件得到重新处理。并且通过入队前判断 FIFO 队列中是否已经有了更新版本的 event,来决定是否丢弃 Indexer 缓存不进行 Resync 入队。在处理 Delta FIFO 队列中的 Resync 的事件数据时,触发 onUpdate 回调来让事件重新处理。 |
|
@lianghao208 Hi "在处理 SharedInformer 事件回调时,让处理失败的事件得到重新处理"。 这里应该会将处理过的事件也进行了一次update处理吧? |
是的,准确的说时update处理,我改一下表述,感谢指正~ |
|
这个问题在《Programming Kubernetes》的第一章详细解释了一遍,我搬运一下。 主要的目的是为了不丢数据,处理 以下内容都摘抄自《Programming Kubernetes》
|

学习了~ 感谢~ |
|
|
@gaorong 感谢解惑。对第2点的回答还有两个疑问:
从这句话字面上我理解的意思是说:如果网络只是短暂波动的话,watch 长连接会存在某种重试机制吗?那么这种重试机制是informer 自身实现的吗?或者还是借助http自身就有的某种机制?
这句话指的是对于informer来说,整体也存在重试机制?也就是再重新执行一开始的list+watch的完整过程:先执行一次list,后面都还走watch跟原来一样,跟重启了一样吗? |
以前看好多 blog 都说 |
这样来看的话,informer能保证event guaranteed. 不会丢失event ? |
启动之后只会list一次(或两次,出错时), 连接watch, 后续等待watch数据. 接收watch数据出错后, 会重新list & watch. |
|
个人理解, resync机制就是为了定时确认当前的状态与目标状态是否一致. |
|
谢谢@gasxia 和 @yutian2011 的解释帮助了理解。 |
|
我想问下,如何让他不list,或者我只关心我需要的数据,不需要全量数据,毕竟数据量太大,全量list占用cpu和内存会较高 |
|
我理解 reSync 机制有两个作用。
关于推荐怎么配置这个时间,我理解就是看你是用来保证第一点,还是第二点。如果是第一点,可以把时间配置的长一些,比如几个小时。如果是第二点,就是看你的系统要求,比如一分钟,几十秒,都是可以的,这里也要考虑 controller 的协调里做的是什么,会不会对外部系统造成很大压力。 |
关于第2点谈一下个人愚见哈。 我觉得楼主讨论的 resync 机制针对的应该是“系统内部”“错过”事件的情况,即,一个资源的变动事件没有被informer接收到,自然也就会被controller错过。resync的存在可以定期让用户自己实现的controller整个过一遍所有资源,从而弥补之前“错过”的事件(因为本质上我们并不是特别关心“发生了什么事件”,而更关心“现在资源的期望状态到底是啥”,而事件的接收更多的起到一个通知的作用,而每次执行controller的reconcile逻辑时都要获取一下资源的最新状态)。 而你这里第2点说的情况,应该是“系统外部”导致的不一致情况。这种应该在用户自定义的controller中的reconcile函数中处理,比如返回值指定requeue参数等。 虽然上述两种情况的结果是相同的(即,本质上都是定期重新reconcile一下资源),但动机不太一样。 |
|
这是来自QQ邮箱的假期自动回复邮件。
您好,我最近正在休假中,无法亲自回复您的邮件。我将在假期结束后,尽快给您回复。
|
|
我看了client-go 1.26版本代码,代码如下(tools/cache/Reflector.go/Run): // Run repeatedly uses the reflector's ListAndWatch to fetch all the
// objects and subsequent deltas.
// Run will exit when stopCh is closed.
func (r *Reflector) Run(stopCh <-chan struct{}) {
klog.V(3).Infof("Starting reflector %s (%s) from %s", r.expectedTypeName, r.resyncPeriod, r.name)
wait.BackoffUntil(func() {
if err := r.ListAndWatch(stopCh); err != nil {
r.watchErrorHandler(r, err)
}
}, r.backoffManager, true, stopCh)
klog.V(3).Infof("Stopping reflector %s (%s) from %s", r.expectedTypeName, r.resyncPeriod, r.name)
}这里的BackoffUntil应该会定期的执行ListAndWatch方法,看起来list函数会定期的从kube-apiserver获取数据 |
多久一次?可能默认为了保证数据一致性? |
@lightnine |
|
这是来自QQ邮箱的假期自动回复邮件。
您好,我最近正在休假中,无法亲自回复您的邮件。我将在假期结束后,尽快给您回复。
|
1 similar comment
|
这是来自QQ邮箱的假期自动回复邮件。
您好,我最近正在休假中,无法亲自回复您的邮件。我将在假期结束后,尽快给您回复。
|

I find the author's answer from the book-programming Kubernetes |
|
这是来自QQ邮箱的假期自动回复邮件。
您好,我最近正在休假中,无法亲自回复您的邮件。我将在假期结束后,尽快给您回复。
|
“让 Indexer 周期性地将缓存同步到队列中”,请问一下这里的意思是把local store的事件列表重新和DeltaFIFO中的事件进行对比吗?本地缓存是对象的值,而DeltaFIFO存储的是事件。我不太明白为什么二者存储的东西不一样,但是能同步? |
|
这是来自QQ邮箱的假期自动回复邮件。
您好,我最近正在休假中,无法亲自回复您的邮件。我将在假期结束后,尽快给您回复。
|
Resync 机制会将 Indexer 的本地缓存重新同步到 DeltaFIFO 队列中。一般我们会设置一个时间周期,让 Indexer 周期性地将缓存同步到队列中。直接 list/watch apiserver 就已经能拿到集群中资源对象变化的 event 了,这里引入 Resync 的作用是什么呢?去掉会有什么影响呢?
The text was updated successfully, but these errors were encountered: