{kind=link}
This repo contains object oriented spline-fitting code written in c++. Left online as an example for CSE 701.
Plotting code, in Python and Julia, is also provided.
Overview:
Although linear models are often convenient (or even necessary), in realistic applications, whatever function we are estimating is highly likely to be non-linear. This package contains some basis expansion methods for fitting non-linear models. Specifically, it can fit Power Basis regression splines, regression B-Splines, and penalized B-Splines.
The common theme is that, instead of regressing on our vector of inputs directly, we instead augment or replace each input with a corresponding nonlinear transformation at that point, such that the transformations sum linearly to model our target variable.
That is, instead of modelling the relationship as:
We construct
The utility of this approach comes from the fact that, after applying the non-linear transformation, the functions enter the model linearly. This means that the vast array of linear model literature can — in many cases — be adapted to apply to basis expansion methods, a benefit which doesn't appear when using e.g. deep neural networks.
Additionally, unlike some other machine learning methods, these remain (weakly) convex optimization problems, and so we are assured that, if a solution is recovered, it is a globally optimal solution.
The first method available here is a regression spline. We split the data along the time axis into
The power basis representation of a spline is found by augmenting the basis for a polynomial regression problem of that same order with additional basis functions at each knot; this is done to enforce our continuity constraints.
For some degree
$$\begin{array}{lll} b_{n+1}(x) = \left(x-k_{1} \right){+}^{n} , & b{n+2}(x) = \left(x-k_{2} \right)_{+}^{n}, [...] \ \end{array}$$
Where
For data in 'input.csv', we can return a power basis regression spline with:
./splines PowerBasis power knots
for example,
./splines PowerBasis 3 2
Returns a regression spline with degree
| t | y |
|---|---|
| 1 | -0.947246 |
| 1.1 | 0.320104 |
| 1.2 | 1.53814 |
| 1.3 | 2.70769 |
| ... | ... |
Which can be automatically plotted with the attached plotting.py file, returning:
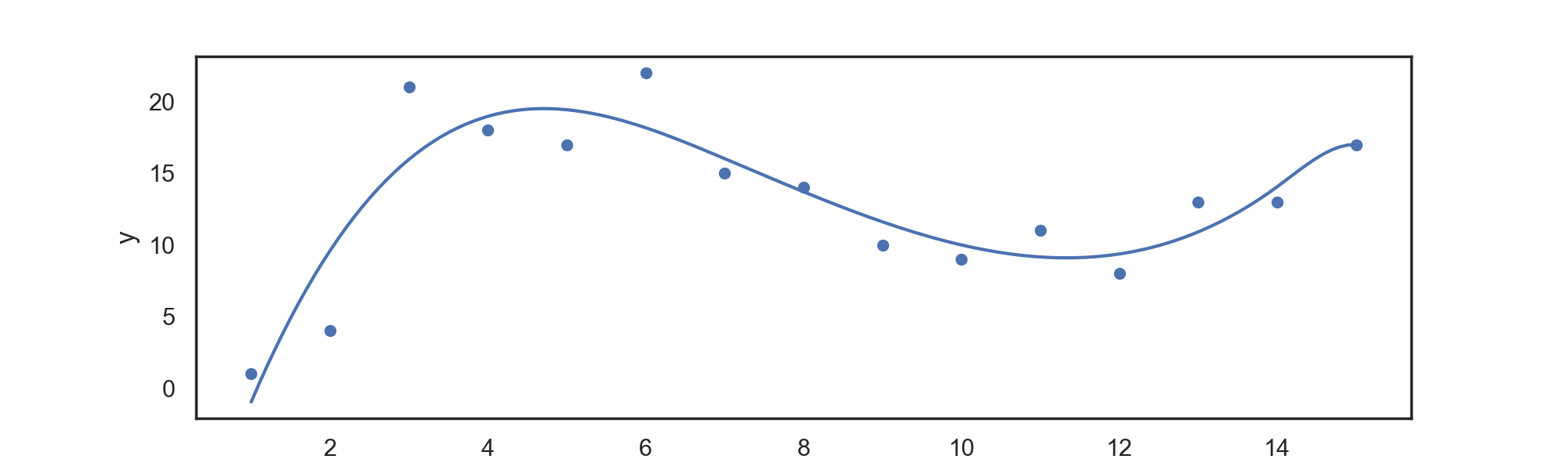
(using the default input.csv provided as data).
Notes:
-
Asking for more knots than datapoints probably won't work, for nearly all regression problems. The program will throw a warning when fitting, and let you know if something went wrong.
-
Larger computations should use B-Splines instead.
Although computationally simple, the power basis provided above has numerous undesirable numerical properties --- specifically, it requires the computation of large numbers, which can lead to rounding problems. To solve this issue, we turn towards an alternative basis construction which can span the same set of functions as a clamped power basis, but which has more desirable numerical properties.
Another advantage to Basis splines is that they are zero for all values far away from knots points, providing local support. This helps avoiding colinearity issues common with other basis representations.
Unlike the power basis, higher order B-spline basis functions have no simple closed form, and must be represented as the iterative convolution of lower order basis functions, where the
For data in 'input.csv', we can return a power B-spline regression spline with:
./splines BSpline power knots
for example,
./splines BSpline 3 6
Returns a regression spline with degree
| t | y |
|---|---|
| 1 | 0.993459 |
| 1.1 | -1.38922 |
| 1.2 | -2.93915 |
| 1.3 | -3.74152 |
| ... | ... |
Which can be automatically plotted with the attached plotting.py file, returning:
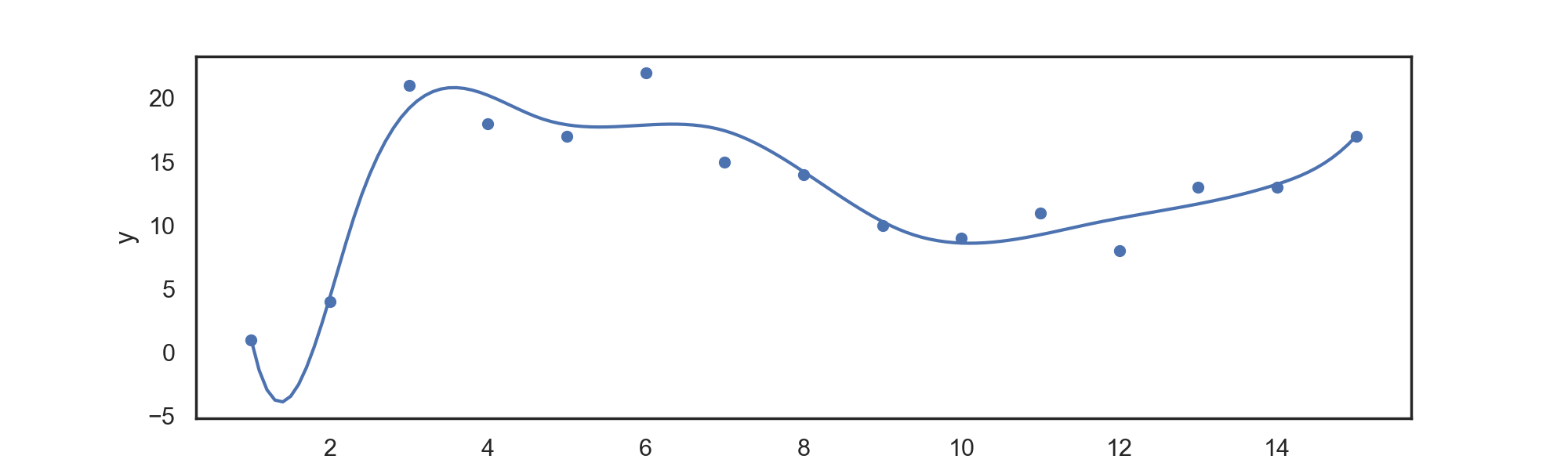
This program can also perform simple polynomial regression, for testing purposes.
For data in 'input.csv', we can return a polynomial regression fit with:
./splines PolynomialRegression power
For example:
./splines PolynomialRegression 2
For a quadratic regression fit, which can be automatically plotted with the included script, returning:
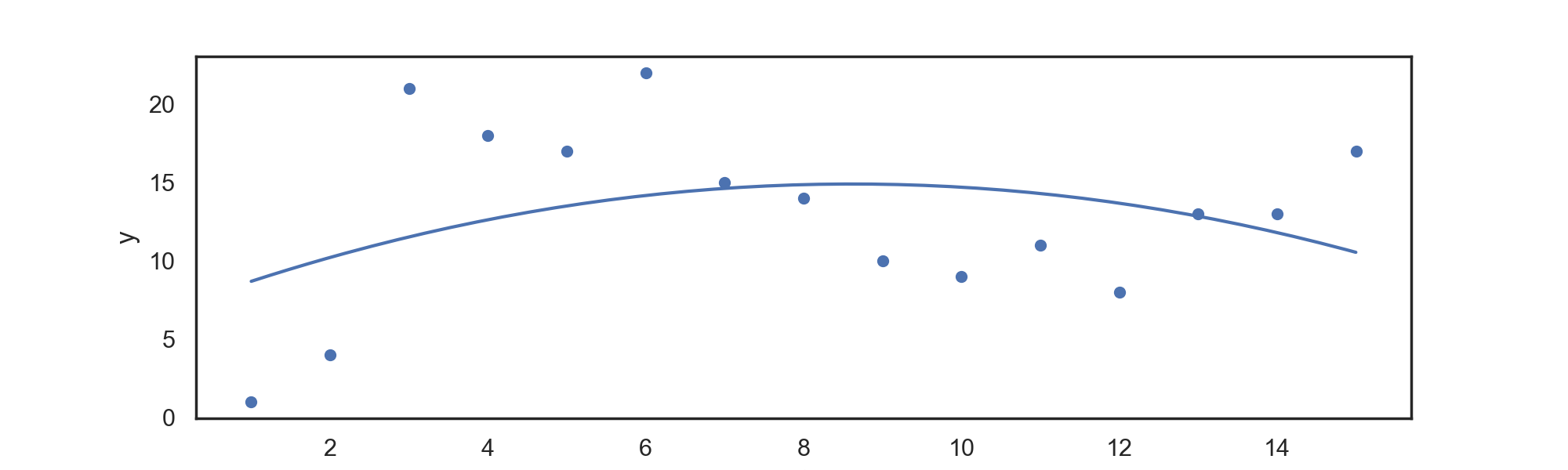
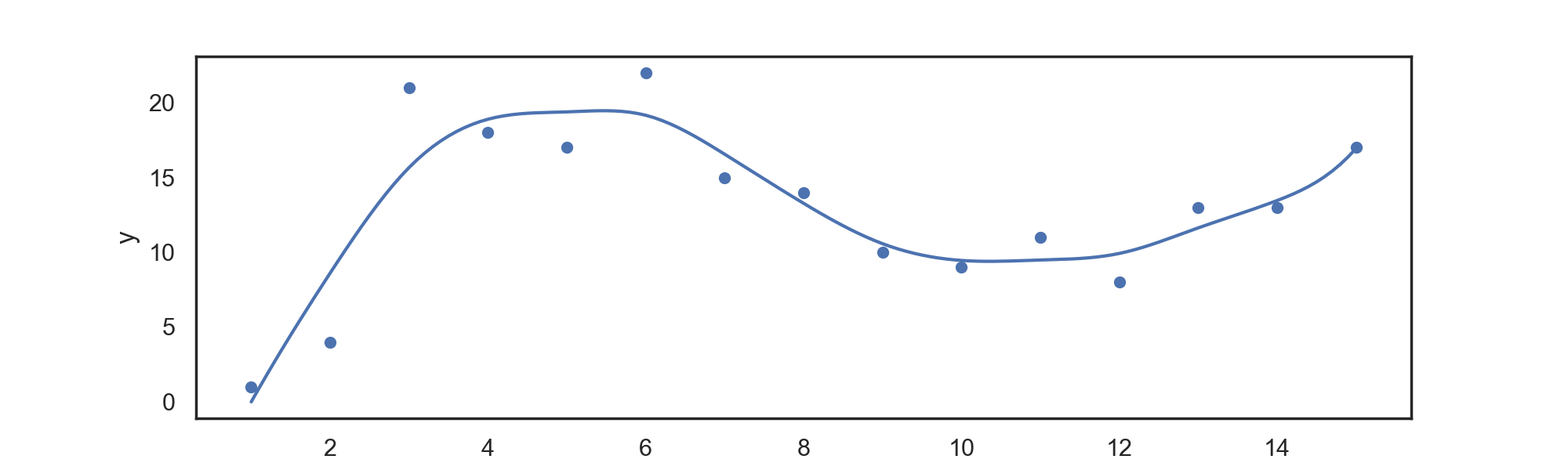
Smoothing Splines
Seeking to avoid questionable heuristics around automatic knot number and location, we assign the maximal number of knots (equal to number of data points), and then penalize the parameters on each individual basis function during fitting. Keeping with tradition, we penalize wigglyness, given by:
for basis function
For data in 'input.csv', we can return a B-spline smooth with:
./splines Smooth lambda
for example,
./splines Smooth 0.4
Returns a smooth with wiggliness parameter lambda.
| t | y |
|---|---|
| 1 | -0.00671362 |
| 1.1 | 1,0.920172 |
| 1.2 | 1.82914 |
| 1.3 | 2.72146 |
| ... | ... |
Which can be automatically plotted with the attached plotting.py file, returning:
Automatic Determination of Lambda
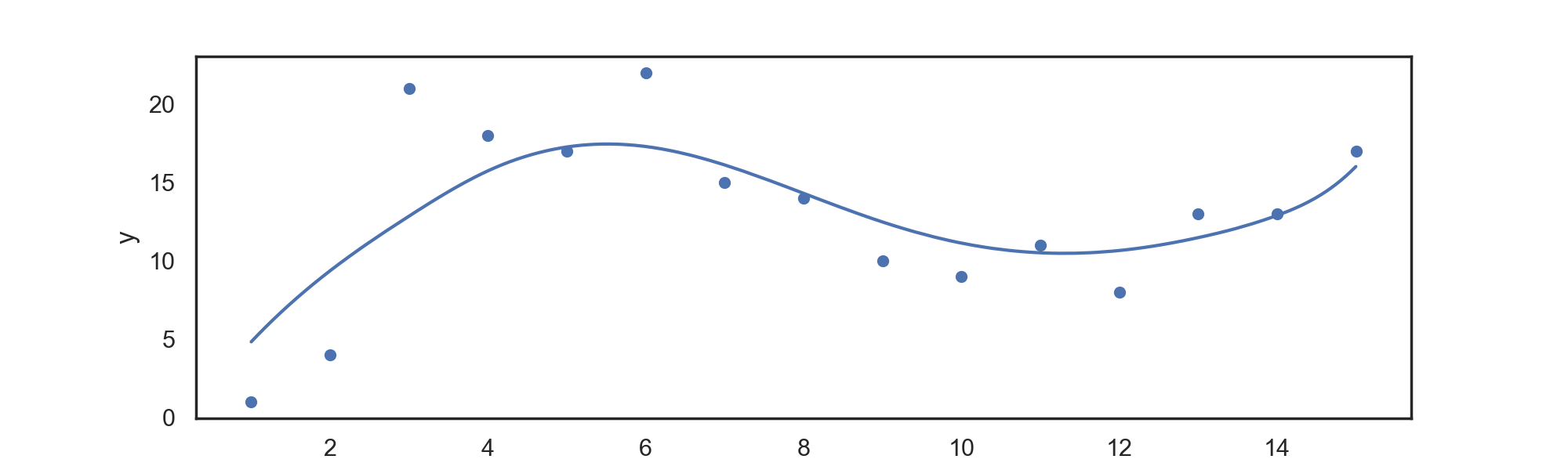
Our main concern in this case is one of overfitting — to avoid this, we need to choose lambda such that our model is not overly smooth (maximal bias), and not overly sensitive to individual data (maximal variance).
Attempt to select lambda by hand can work, but ideally we'd like some sort of automatic criteria to select lambda such that we avoid overfitting on the data.
The standard approach is to use some sort of cross validation, portioning the data into different train and test sets to evaluate generalization error.
Here we use Leave One Out cross validation, fitting the data to everything except for one data point, and then testing our performance on that one datapoint, iterating over all the data. That is, for $\hat f^{[-1]}_i $ — the model fit to all data except
$$\mathcal{V}{o}=\frac{1}{n} \sum{i=1}^{n}\left(\hat{f}{i}^{[-i]}-y{i}\right)^{2}$$
(Wood 2006), seeking to select lambda such that we minimize
$$\mathcal{V}{o}=\frac{1}{n} \sum{i=1}^{n}\left(y_{i}-\hat{f}{i}\right)^{2} /\left(1-A{i i}\right)^{2}$$
Deriving the general cross validation score:
$$\mathcal{V}{g}=\frac{n \sum{i=1}^{n}\left(y_{i}-\hat{f}_{i}\right)^{2}}{[n-\operatorname{tr}(\mathbf{A})]^{2}}$$
Where
Note: Although this is computationally much cheaper than calculating a new smooth for each datapoint, this is still extremely costly, and can take a while computationally.
To use this method, request 'auto' as the lambda parameter, e.g.
./splines Smooth auto
Returns a smooth with automatically determined wiggliness parameter.
Non-trivial algorithms (e.g., anything more complicated than constructing a Vandermonde matrix:)
Cox De Boor Recurrence
Setting a base case as the degree zero basis function — given by an indicator function between knots — we evaluate:
For:
- Knots
$t_m$ - Real number
$x$ - Basis of degree
$p$
Where each
GCV
Seeking to avoid calculating new scores for each point in a leave-one-out cross validation test, we employ a clever trick, fitting the model once per
$$\mathcal{V}{g}=\frac{n \sum{i=1}^{n}\left(y_{i}-\hat{f}_{i}\right)^{2}}{[n-\operatorname{tr}(\mathbf{A})]^{2}}$$
Where
-
$y_i$ is the dropped point. -
$\hat f_i$ is the function evaluated at that point.- This is essentially the Sum of Squared Errors.
- Divide out by the number of points minus the trace of the Hat Matrix.
- The hat matrix is a [data, data] sized matrix that produces the model fits when multiplied by the predictor variables.
- Given by
$\mathbf{X}\left(\mathbf{X}^{\top} \mathbf{X}+\lambda \mathbf{S}\right)^{-1} \mathbf{X}^{\top}$
Gaussian Elimination
With one exception, systems are solved in this package via Gaussian elimination (instead of calculation of the inverse), and then back substitution. This algorithm is not the focus of the project, but it plays a key role, so a description here seems useful.
- The goal is to solve a system of type "X \ y" in Matlab / Julia notation.
- Augment X with vector y on the right hand side.
- Loop over all the columns
- Loop over all the rows
- For any value below a pivot, calculate the new value required such that subtracting the multiple of this value times the pivot from the target row will make the original value zero.
- Add a the pivot row multiplied by this value to that entire row.
- Repeat until the matrix is upper triangular.
- Loop over all the rows
- Starting with the last element of the lower triangular matrix, construct the solution vector by iterating up over the rows of the matrix.
Due to the matrix inverse being ill-conditioned, this is vastly preferable to explicit computations of
In the case of an explicit inverse, the above algorithm was modified slightly:
- Augment with an identity matrix.
- Eliminating all off-diagonal elements.
- Set pivots to zero.
- Return resultant transform of identity as matrix inverse.
This is far from ideal, but for the crude computation of GCV that it is used for, it doesn't totally vitiate the project.