polardb support survey
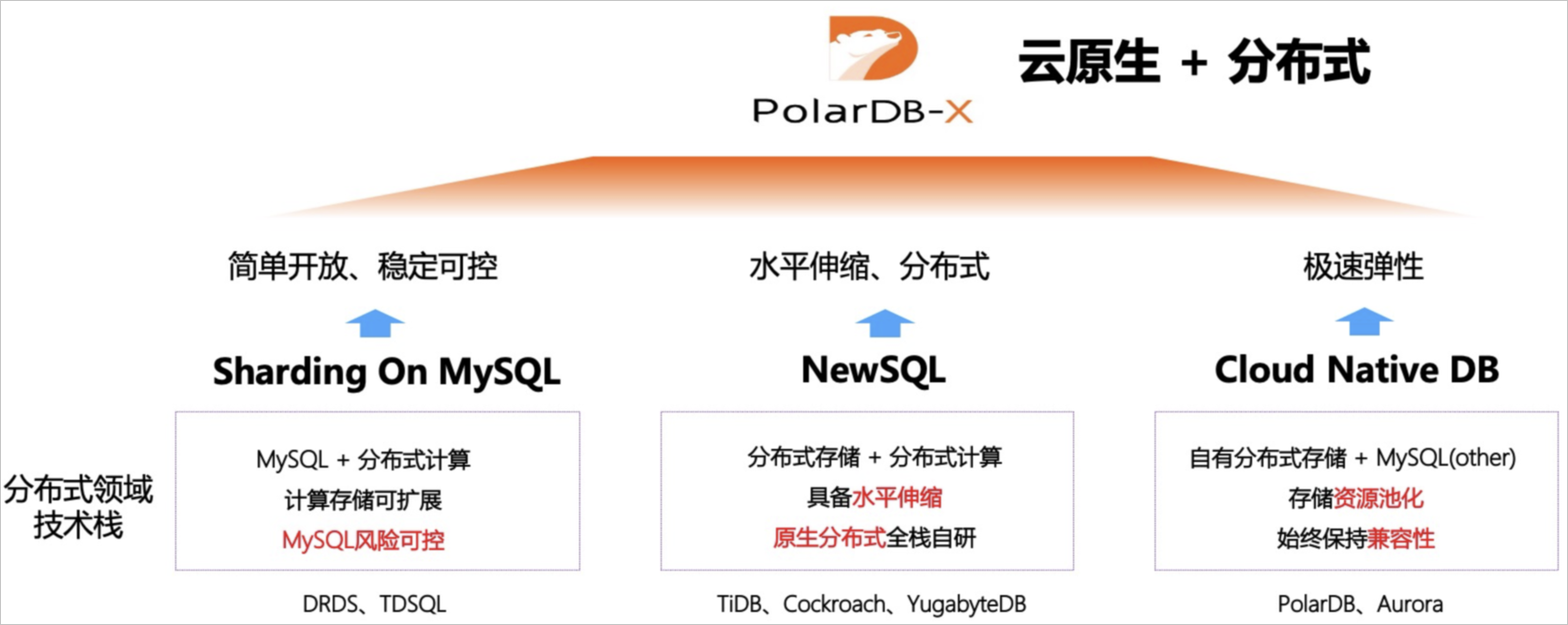
当前,分布式数据库领域有3大技术方向:Sharding技术,NewSQL原生分布式技术,云原生DB技术。每种分布式都有其独特的优势和特点。PolarDB-X的架构继承了DRDS和X-DB技术的稳定性,结合了PolarDB的云原生技术,融入了NewSQL对于分布式数据一致性的能力,提供新的云原生+分布式的产品。
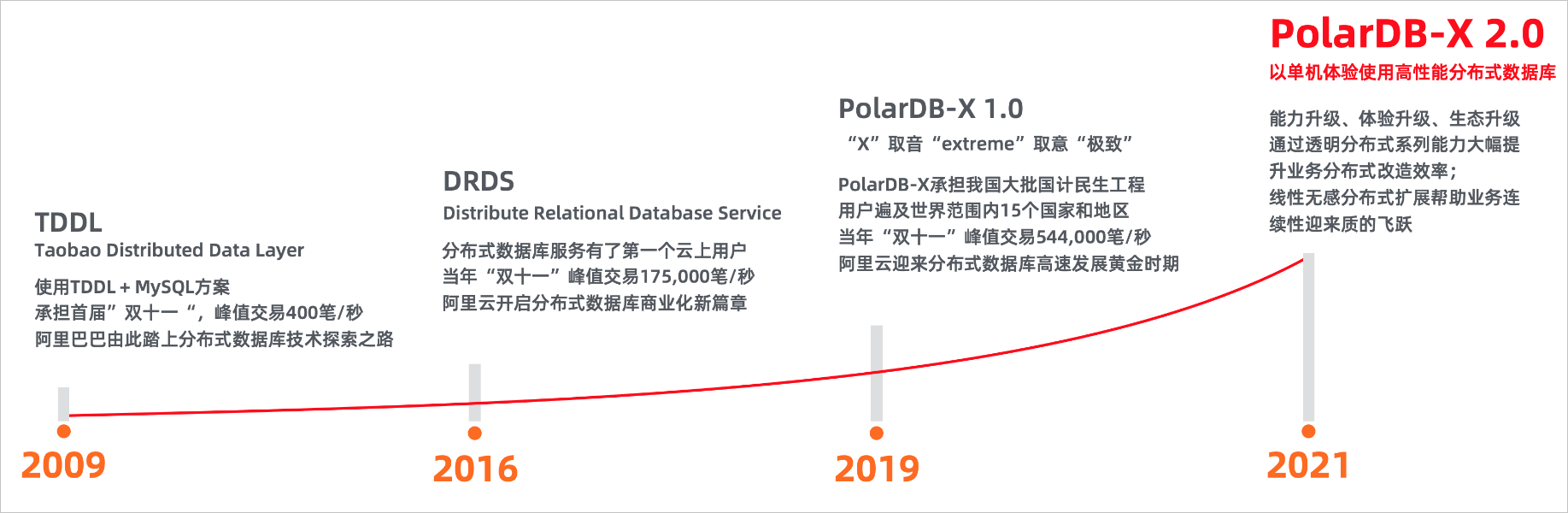
- 2009年,阿里面临数据资源需求与业务增长之间的鸿沟。为弥补这一差距,提出了“去IOE”理念,由此从纵向扩展到横向扩展,由商业软件到开源软件,为云计算铺路。
- TDDL阶段,阿里开始实践"去IOE"理念(key:阿里内大规模应用;开创分库分表技术)。同年11月,发布了TDDL(Taobao Distributed Data Layer),这是阿里对高并发交易系统的一个开源数据库解决方案。凭借其独特的三层拆分结构,TDDL在2011-2015年间成为阿里的统一接入标准,广泛应用于多个业务领域。
- DRDS阶段(key:云端商业化;高性能SQL引擎)。2016年,阿里巴巴进一步推动其分布式数据库技术,开发了DRDS(Distributed Relational Database Service)。DRDS不仅持续强化SQL引擎性能,还积极为公有云用户提供服务。这个阶段标志着从中间件向真正的分布式数据库系统迈进。
- 2019年,PolarDB-X正式被提出(key:架构与品牌升级)。由DRDS转型为PolarDB-X 1.0,其不仅继承了DRDS的所有优点,还加入了更多企业级特性,支持以PolarDB MySQL为存储节点,强化了安全性和可靠性。PolarDB-X 1.0支持以PolarDB MySQL作为存储节点,大幅提高集群IO能力以及柔性分布式事务,且面向政企客户需求增强了安全特性,例如,一致性备份恢复、SQL闪回、SQL审计等。
- PolarDB-X 2.0阶段(key:透明分布式、开源)。2.0基于透明分布式理念提供了默认主键拆分策略、基于TSO和MVCC的高性能强一致分布式事务、基于一致性Hash分区策略的分布式线性扩展能力、全局一致性Binlog和全局一致性备份能力。数据节点(DN)采用阿里自研的基于X-Paxos的三副本强一致MySQL分支,确保在容灾过程中RPO=0。这一版本全面采纳了开源,在全球范围内扩大了服务,并开始为未来探索,包括国产化、HTAP混合负载等多个方向。
1.0(DRDS)和2.0都基于存储计算分离的Shared-Nothing架构,最大限度地发挥弹性扩展能力。
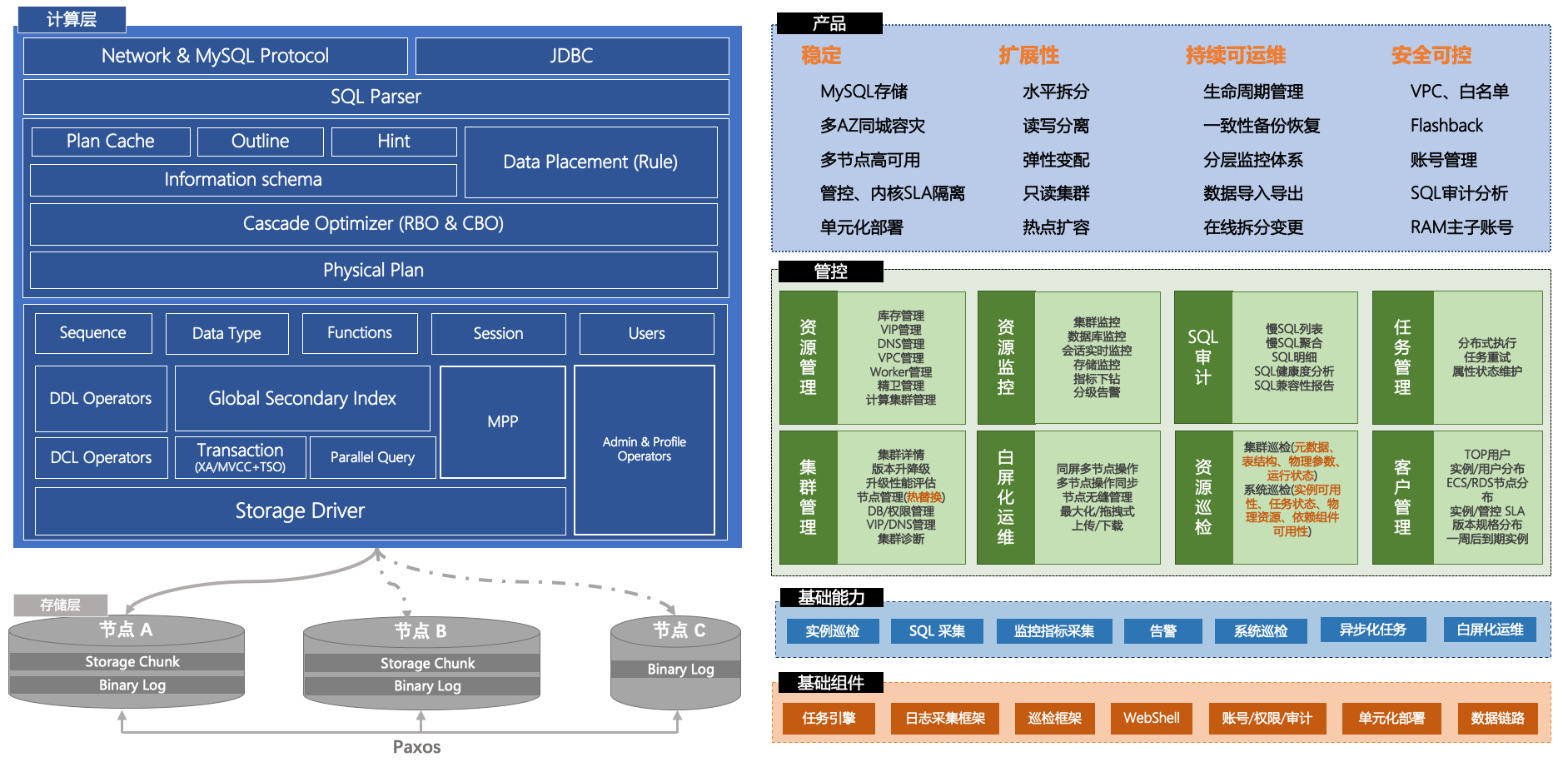
- CN(全称:Compute Node/计算节点),主要提供分布式SQL引擎,解决分布式事务协调、优化器、执行器等。
- DN(全称:Data Node/存储节点),主要提供数据存储引擎,比如InnoDB和自研存储引擎(X-Engine和神秘列存),解决数据一致性和持久化,并提供计算下推能力满足分布式要求(比如Project/Filter/Join/Agg等下推计算),可支持本地盘和共享存储。
- GMS(全称:Global Meta Service/全局元数据服务),主要提供分布式下元数据和全局授时服务,比如TSO、表的metadata信息等。
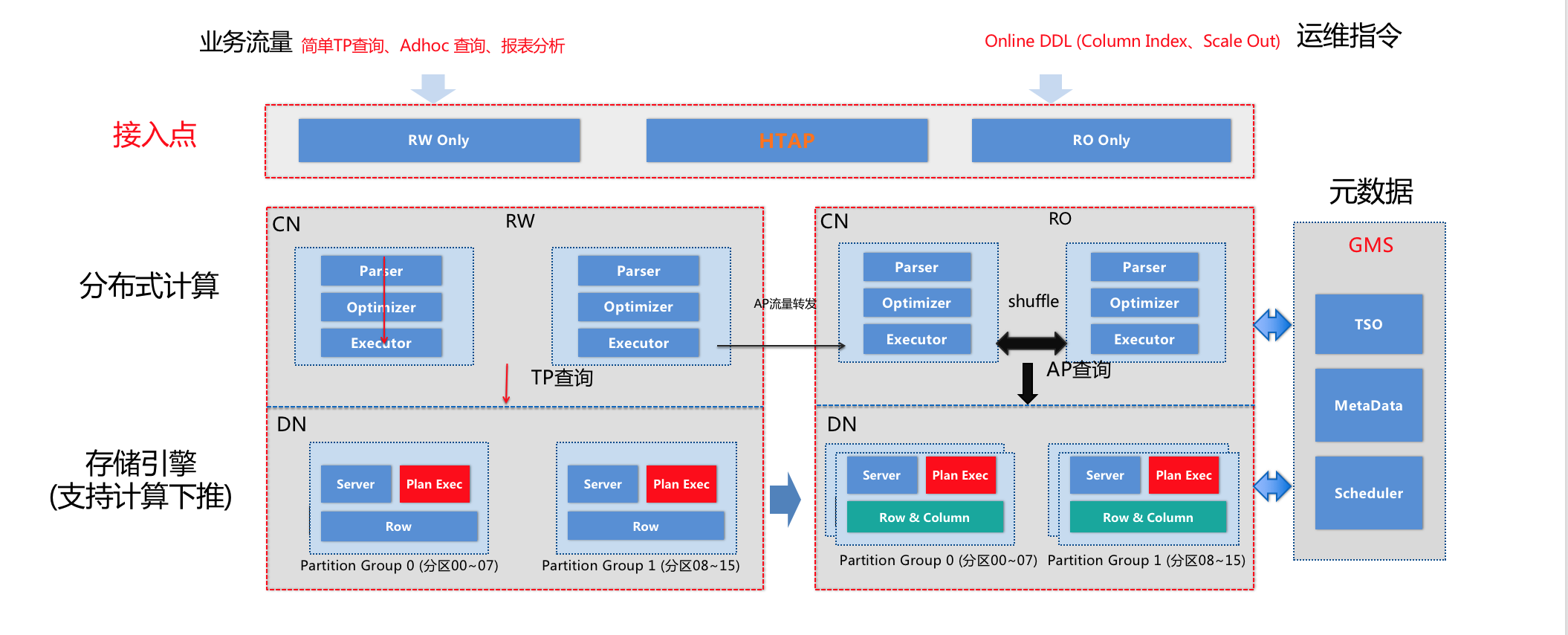
除此以外,会有专门的接入点(endpoint)的设计,可以理解为基于负载均衡设备提供的vip/dns。一个数据库实例可以有不同策略的节点,比如HTAP endpoint,会基于全局版本号、智能策略分流OLTP和OLAP到不同副本上,满足混合负载下的强一致、强隔离的诉求。
以下不罗列对比所有调研的1.0 vs 2.0的特性,例如混合负载HTAP、全链路监控和审计等,重点关注适配Seata所关注的两者架构差异、分布式事务实现、以及与MySQL的兼容性。
1.0的拓展性原理?
对于PolarDB-X 1.0来说,其架构继承了更多DRDS的特性,作为Proxy层,后端由计算层实例与存储层私有定制RDS实例组成,通过挂载多个MySQL进行分库分表水平拆分,对应到MySQL的partition上。通过这种将数据分散到多个存储资源MySQL的方式,实现获取数据读写并发和存储容量分散的效果。
1.0如何迁移和扩容?
和传统的DRDS拓展一样,1.0具备数据水平拆分的能力,可以将数据库数据按某种规则分散存储到多个MySQL数据库上,对外服务尽可能保证如同单MySQL数据库体验。拆分后,在MySQL上物理存在的数据库称为分库,物理的表称为分表(每个分表数据是完整数据的一部分)。通过增加RDS/PolarDB MySQL实例数,将原有的分库迁移到新的RDS/PolarDB MySQL实例上,达到扩容的目标。
2.0的拓展性原理?
而PoalrDB 2.0的拓展方式随着架构演进发生了较大变化,更注重分布式的线性拓展。2.0将数据表以水平分区的方式,分布在多个存储节点(DN)中。数据分区方式由分区函数决定,支持哈希(Hash)、范围(Range)等常用的分区函数,SQL层将会自动完成查询路由、结果合并等。
2.0如何迁移和扩容?
当新的数据节点加入实例时,PolarDB-X将自动触发扩容任务,将数据进行再平衡(Rebalance)。
以下图为例,orders表原本分布在4个数据节点上。用户进行扩容后,实例的数据节点数量从4个增加到6 个,触发PolarDB-X的再平衡任务,将部分数据分区从旧节点移动到新节点上。这一过程在后台利用空闲资源完成,对业务线上流量无影响。
- 高可用
经过阿里多年双11验证的X-DB(X-Paxos共识协议能力),提供数据强一致,保证节点故障切换时 RPO=0。另外支持多样化的部署和容灾能力,比如基于Paxos强同步的同城三机房、三地五中心,另外搭配binlog异步复制的两地三中心、异地灾备、异地多活等。尤其在异地长距离传输上,基于 Batching & Pipelining 进行网络优化来提升性能。
- 高兼容
PolarDB-X主要兼容MySQL,包括SQL、函数类型等,技术上引入全局时间授时服务,提供全局一致性的分布式事务能力,通过TSO+2PC提供数据库完整的ACID能力,满足分布式下的Read-Commited/Repeatable-Read的隔离级别。同时在分布式事务的基础上,提供全局二级索引能力,通过事务多写保证索引和主表数据强一致的同时,引入基于代价的CBO优化器实现索引选择。除此以外,在元数据和生态对接层面,PolarDB-X基于Online DDL的技术提供了分布式下元数据的一致性。同时硬件层面,兼容主流国产操作系统和芯片认证,比如麒麟、鲲鹏、海光等。 另外在业界主流的分布式数据库里,分布式下的redolog/binlog等数据库变更日志其实一直被厂商所忽视,从关系数据库的发展历史来看,生态和标准对于市场规模化非常重要,PolarDB-X 2.0会支持全局binlog能力,全面兼容和拥抱MySQL数据库生态,用户可以将PolarDB-X当做一个MySQL库,采用标准的binlog dump协议获取binlog日志。
- 高扩展
PolarDB-X基于Share-Nothing的架构支持水平扩展,同时支持数据库在线扩缩容能力,在OLTP场景下可支持千万级别的并发、以及PB级别的数据存储规模,同样在OLAP场景下,引入MPP并行查询技术,扩展机器后查询能力可线性提升,满足TPC-H等的复杂报表查询诉求。
- HTAP
随着移动互联网和Iot设备的普及,数据会产生爆炸式的增长趋势,传统的OLTP和OLAP的解决方案是基于简单的读写分离或者ETL模型,将在线库的数据T+1的方式抽取到数据仓库中进行计算,这种方案存在存储成本高、实时性差、链路和维护成本高。PolarDB-X 2.0设计中支持OLTP和OLAP的混合负载的能力,可以在一个实例里同时运行TPC-C和TPC-H的benchmark测试,保证AP的查询不影响TP流量的稳定性。核心技术层面也有创新性,比如会在计算层精确识别出TP和AP的流量,结合多副本的特性和多副本的一致性读能力,智能将TP和AP路由到不同的副本上,同时在AP链路上默认开启MPP并行查询技术,从而在满足隔离性的基础上,线性提升AP的查询能力。在存储层上,也在完善计算下推能力,未来也会提供高性能列存引擎,实现行列混合的HTAP能力。
- 极致弹性
PolarDB-X结合PolarDB云原生的技术,可以基于PolarDB的共享存储+RDMA网络优化能力,提供秒级备份、极速弹性、以及存储按需扩展的能力。基于共享存储的基础上,结合分布式的多点写入能力,可以在不迁移数据的前提下提供秒级弹性的能力,给到用户完全不一样的弹性体验。
- 开放生态
PolarDB-X全面拥抱和坚定MySQL的开源生态,做到代码完全自主可控的同时满足分布式MySQL的兼容性,架构做到简单开放,只要具备一定MySQL背景的同学即可完成持续运维。除此以外,PolarDB-X和阿里云的数据库生态有完整的闭环对接,支持如DTS/DBS/DMS等,可打通阿里云的的整个大生态。
1.0,针对MySQL 5.6版本用户,或PolarDB-X 1.0版本低于5.3.4:对于MySQL 5.6版本,由于MySQL XA协议实现尚不成熟,PolarDB-X 1.0自主实现了2PC事务策略用于分布式事务。
1.0,针对MySQL版本≥5.7,并且PolarDB-X 1.0版本≥5.3.4:对于MySQL 5.7及更高版本,PolarDB-X 1.0默认基于XA事务协议进行分布式事务。具体地,PolarDB-X 1.0分布式事务使用体验和单机MySQL数据库完全一致,例如:SET AUTOCOMMIT=0开启一个事务;COMMIT提交当前事务;ROLLBACK回滚当前事务。如果事务中的SQL仅涉及单个分片,1.0会将其作为单机事务直接下发给MySQL;如果事务中的SQL语句修改了多个分片的数据,1.0会自动地将当前事务升级为分布式事务。
1.0中的柔性事务?区别传统的两阶段提交 (XA) 事务,基于最终一致性原理的 “柔性事务” 能够更好的满足应用的高性能与高可用要求。如果一个事务同时修改多个分库的数据,无法简单保证所有分库一定都能提交成功。如果在事务提交过程中出错,会出现一些分库提交成功、另一些分库失败回滚,产生数据不一致。因而无法保证事务的原子性。而PolarDB-X 1.0柔性事务在涉及多个分库时,将根据SQL语句的含义自动生成相应的补偿操作;一旦发生 “一些分库提交成功、另一些分库提交失败” 的情况,PolarDB-X 1.0用记录的补偿操作撤消之前的修改,从而保证事务的原子性,实现数据的最终一致。类似Seata AT的做法,重点在于拦截具体的 SQL 语句、存储数据操作前后快照、引入全局锁保证事物间写隔离、自动生成反向补偿 SQL 语句等,但此处的事务维度在于分库分表层,而不是业务层面面向数据源的事务。
2.0如何做到强一致的分布式事务?2.0中,架构发生了较大变化,通过引入中心授时服务(TSO),结合多版本并发控制(MVCC),确保读取到一致的快照,而不会读到事务的中间状态。如下图所示,提交事务时,计算节点(CN)执行事务时从TSO获取到时间戳,随着数据一同提交到存储节点(DN)多版本存储引擎上,CN通过读取快照时间戳去DN上读取相应版本的数据。
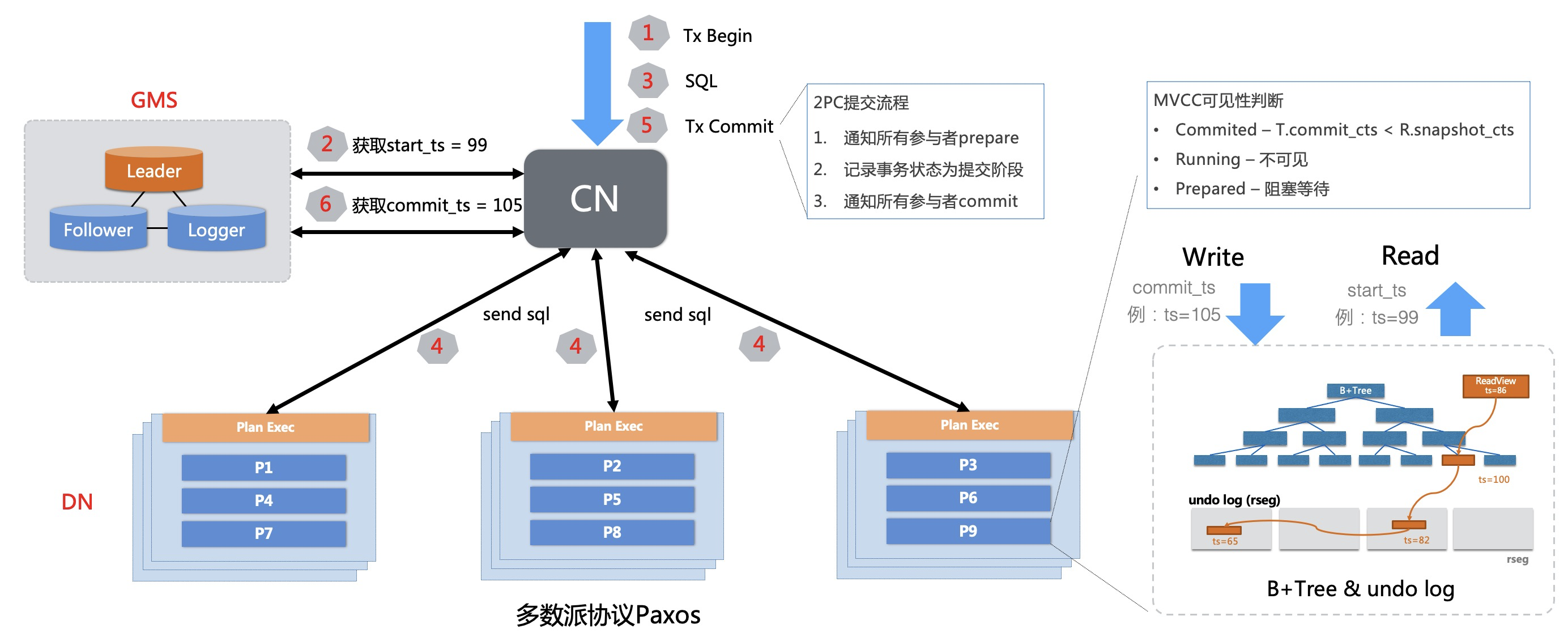
BEGIN;
UPDATE account SET balance = balance - 20 WHERE name = 'Alice';
UPDATE account SET balance = balance + 20 WHERE name = 'Bob';
COMMIT;如果事务内写入的数据涉及多个分区,2.0的计算节点将会使用2PC提交事务,即便在事务提交过程中发生节点宕机等问题,基于2PC的事务恢复机制也能确保事务原子性。 2.0的MVCC多版本(如何快照读?)以上面的转账场景为例,如何在转账的同时查询所有账户的余额总额(“对账”):
SELECT SUM(balance) FROM account;因查询操作的数据涉及多个分区,2.0首先会获取中心授时确定读取版本,读取过程中会对每行数据的MVCC多版本进行可见性判断,确保只会读取在全局时间戳之前已完成提交的事务。 例如转账事务在多个数据节点的提交有先后时间差,已提交的分支事务因为数据版本号不满足可见性,正在提交的事务数据全部不可见,从而确保总额数据读取的一致性。
1.0中:相对2.0,存在部分兼容性问题,官网称支持90%MySQL语法 1.0不兼容的部分语法都有哪些?参见SQL使用限制 1.0是否支持让SQL在指定的分库上执行?参见指定分库执行SQL 1.0中对分表键做UPDATE操作时会报错?是否支持对拆分键字段的值进行修改?1.0实例从V5.4.7-16000638版本开始支持UPDATE更新逻辑表的拆分键字段。因此,若在对分表键做UPDATE操作时出现报错的情况,先查看实例版本是否大于或等于V5.4.7-16000638,否则建议升级版本至V5.4.7-16000638及以上后,再尝试UPDATE操作 1.0支持MySQL的存储过程、跨库外键和级联删除等高级特性吗?1.0不支持存储过程、跨库外键和级联删除。如果需要自定义函数,请尝试通过组合MySQL标准函数解决。参见SQL使用限制 ...... 2.0中:官网称100%兼容MySQL生态 MySQL协议 PolarDB-X通讯协议兼容MySQL协议,可以使用常见的驱动直接连接到PolarDB-X实例,包括JDBC Driver、ODBC Driver、Golang Driver等,并且兼容MySQL SSL、Prepare、Load等传输协议。 SQL兼容性 PolarDB-X 2.0兼容MySQL的各种DML、DAL、DDL语法,其中包括:
- 兼容绝大部分MySQL函数(包括JSON函数、加密解密函数等)。
- 兼容MySQL 8.0的视图、CTE、窗口函数、分析函数等。
- 支持MySQL的各种数据类型,包括类型精度的支持(比如时间戳、Decimal类型)。
- 兼容常见的MySQL字符串Charset及Collation。
- 兼容绝大部分information_schema视图。
ACID事务 PolarDB-X 2.0 事务采用基于乐观读(ReadView)、悲观锁的设计,支持ANSI标准中的四种隔离级别,且行为和MySQL一致。与MySQL相同,PolarDB-X默认采用可重复读(Repeatable Read)隔离级别,该级别下更新范围条件会引入间隙锁(Gap Lock)。PolarDB-X基于回滚段的MVCC机制对大事务比较友好,可支持小时级长时间事务、GB级写入量大事务。
从已有资料来看,PolarDB-X 开源版和企业版的架构一致,共有的核心功能有分布式DDL引擎、私有协议+线程池、扩缩容、扩缩容、读写分离、X-Poxos协议等,开源版额外支持了国产化兼容的功能,企业版提供了更专业更稳健的高可用服务。
PolarDB-PG采用存储和计算分离的架构,所有计算节点共享一份数据,提供分钟级的配置升降级、秒级的故障恢复、全局数据一致性和免费的数据备份容灾服务。100%兼容PostgreSQL 11(开源 & 企业),PostgreSQL 14(企业),高度兼容Oracle。 主要特性
- 计算与存储分离,共享分布式存储。
采用计算与存储分离的设计理念,满足业务弹性扩展的需求。各计算节点通过分布式文件系统(PolarFileSystem)共享底层的存储(PolarStore),极大降低了用户的存储成本。
- 一写多读,读写分离。
PolarDB集群版采用多节点集群的架构,集群中有一个主节点(可读可写)和至少一个只读节点。当应用程序使用集群地址时,PolarDB通过内部的代理层(PolarProxy)对外提供服务,应用程序的请求都先经过代理,然后才访问到数据库节点。代理层不仅可以做安全认证和保护,还可以解析SQL,把写操作发送到主节点,把读操作均衡地分发到多个只读节点,实现自动的读写分离。对于应用程序来说,就像使用一个单点的数据库一样简单。
存储计算分离架构概述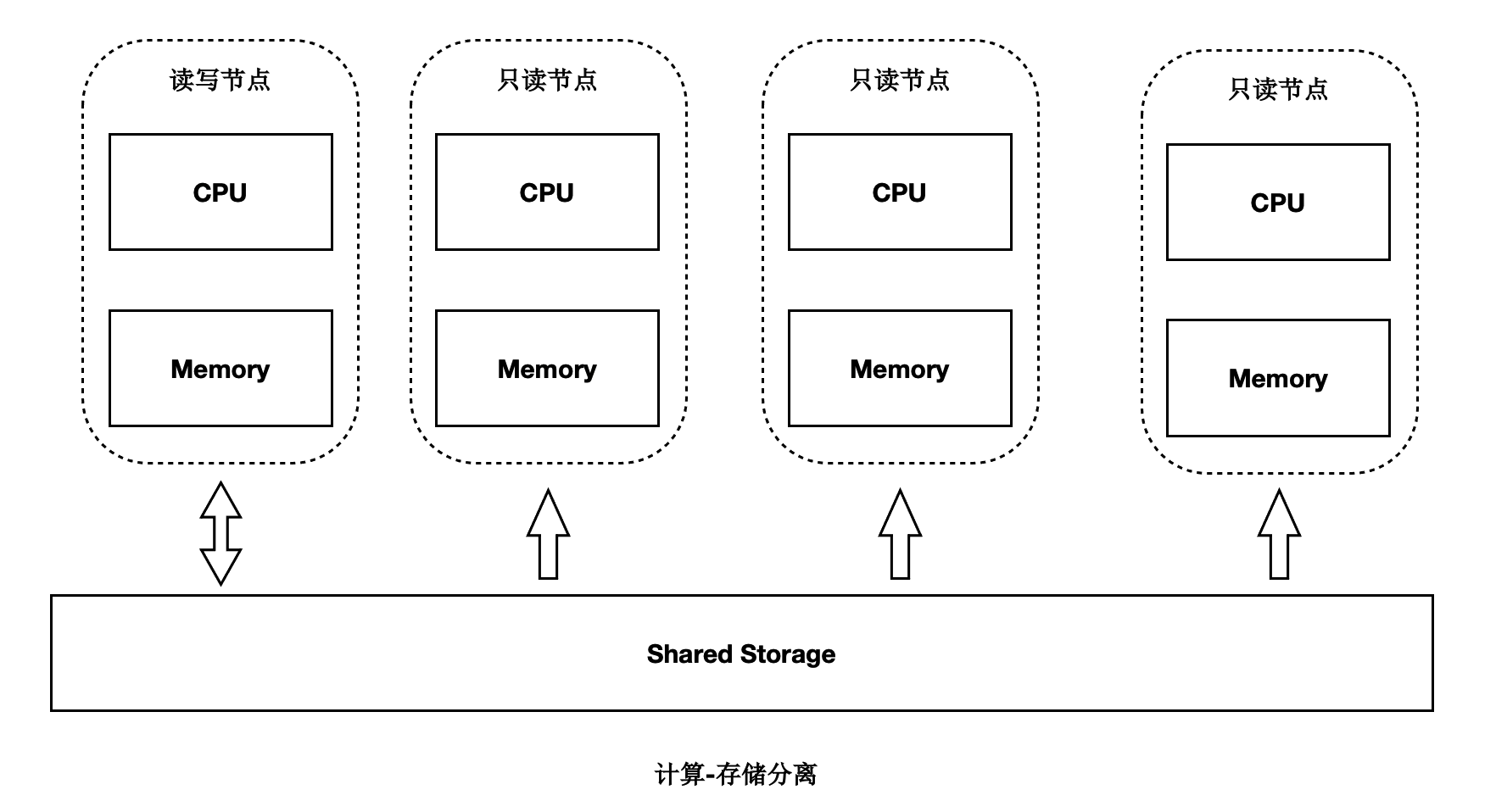
- 当计算能力不够时,可以单独扩展计算集群。
- 当存储容量不够时,可以单独扩展存储集群。
基于Shared-Storage,主节点和多个只读节点共享一份存储数据,主节点刷脏不能再按照传统的刷脏方式,否则会导致以下问题:
- 只读节点在存储中读取的页面,可能是比较老的版本,不符合当前的状态。
- 只读节点读取到的页面比自身内存中想要的数据要超前。
- 主节点切换到只读节点时,只读节点接管数据更新时,存储中的页面可能是旧的,需要读取日志重新对脏页的恢复。
对于第一个问题,需要有页面多版本能力;对于第二个问题,需要主库控制脏页的刷脏速度。 Shared-Storage带来的挑战 基于Shared-Storage,数据库由传统的Share nothing,转变成了Shared-Storage架构。需要解决以下问题:
- 数据一致性:由原来的N份计算+N份存储,转变成了N份计算+1份存储。
- 读写分离:如何基于新架构做到低延迟的复制。
- 高可用:如何Recovery和Failover。
- IO模型:如何从Buffer-IO向Direct-IO优化。
架构原理
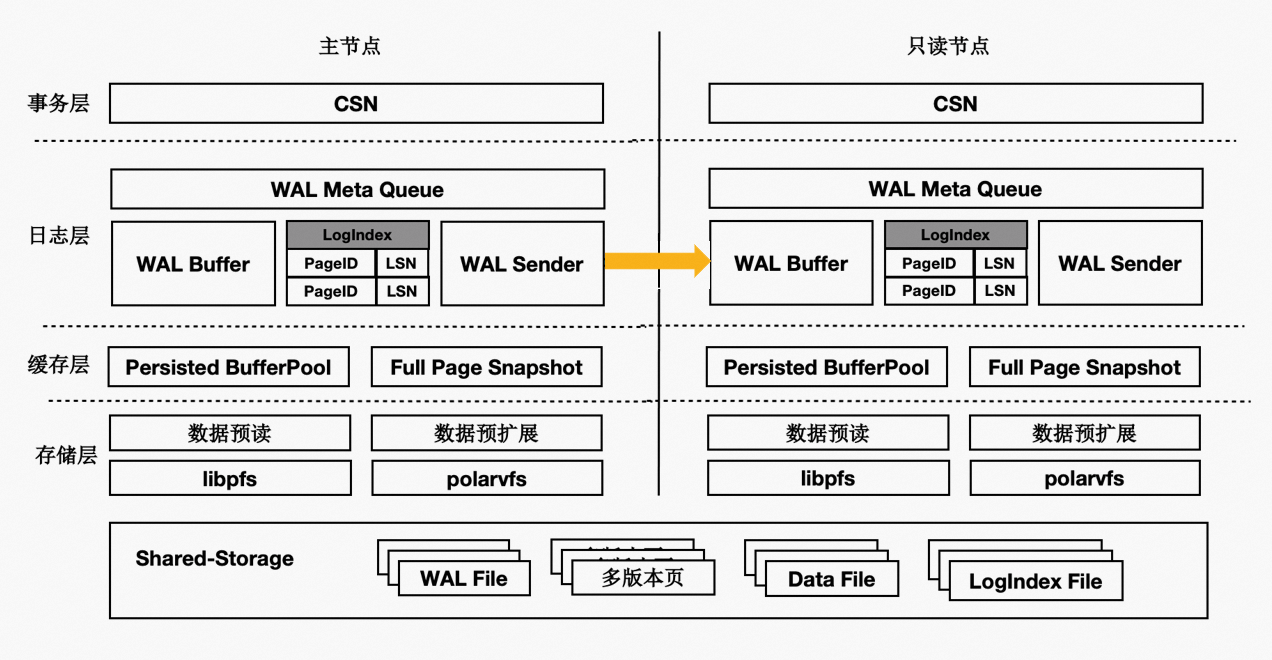
- 主节点为可读可写节点(RW),只读节点为只读(RO)。
- Shared-Storage层,只有主节点能写入,因此主节点和只读节点能看到一致的落盘的数据。
- 只读节点的内存状态是通过回放WAL保持和主节点同步的。
- 主节点的WAL日志写到Shared-Storage,仅复制WAL的meta给只读节点。
- 只读节点从Shared-Storage上读取WAL并回放。
目前,PolarDB开源版支持的是PolarDB for PostgreSQL 11,其与PgSQL的兼容性较好,架构原理与企业版一致。开源版与公共云版共有存储计算分离、一写多读、HTAP混合优化器等功能,但缺少OSS外部表存储、全局临时表、全局索引、闪回,以及一些监控和运维的功能。 PolarDB-PG的企业版,又分为适配PG11和PG14的两个内核小版本,各版本、内核小版本支持的功能差异如下:
| 类别 | 功能 | 内核小版本(PolarDB for PostgreSQL 11) | 内核小版本(PolarDB for PostgreSQL 14) |
|---|---|---|---|
| 高性能 | 预读和预扩展 | V1.1.1 | V14.5.1.0 |
| 表大小缓存 | V1.1.10 | V14.5.1.0 | |
| Global Plan Cache | V1.1.30 | ❌ | |
| 高可用 | 只读节点Online Promote | V1.1.1 | V14.5.1.0 |
| WAL日志并行回放 | V1.1.17 | V14.5.1.0 | |
| Persistent Buffer Pool | V1.1.1 | ❌ | |
| Failover Slot | V1.1.27 | ❌ | |
| Resource Manager | V1.1.1 | V14.5.1.0 | |
| 闪回表 | V1.1.22 | ❌ | |
| 安全 | TDE透明数据加密 | V1.1.1 | V14.5.1.1 |
| HTAP | 自适应扫描 | V1.1.17 | ❌ |
| 实时物化视图 | V1.1.27 | ❌ | |
| 并行DML | V1.1.17 | ❌ | |
| 多级分区表静态裁剪与并行扫描 | V1.1.17 | ❌ | |
| PX性能分析工具 | V1.1.22 | ❌ | |
| 分区表 | 全局索引 | ❌ | V14.6.4.0 |
| 插件 | decoderbufs | V1.1.28 | V14.5.1.0 |
| hll | V1.1.28 | V14.5.1.0 | |
| hypopg | V1.1.28 | V14.5.1.0 | |
| log_fdw | V1.1.27 | V14.5.1.0 | |
| pg_bigm | V1.1.28 | V14.5.2.0 | |
| pg_jieba | V1.1.28 | V14.5.2.0 | |
| sequential_uuid | V1.1.28 | V14.5.1.0 | |
| smlar | V1.1.28 | V14.5.1.0 | |
| wal2json | V1.1.29 | V14.5.1.0 |
PolarDB PostgreSQL版(兼容Oracle)(又称PolarDB-O)和PolarDB-PG的基本架构是一致的,同样采用存储和计算分离、一写多读、读写分离的架构。开发O版的主要目的是基于阿里成功经验的Oracle兼容性,兼容研发人员及DBA使用最多的Oracle语法,避免用户重新学习。配合ADAM数据库和应用迁移平台,提供工程化流程化的迁移能力,实现迁移前评估、迁移过程数据同步及校验、JAVA程序SQL语法兼容发现、迁移后性能对比等全链路迁移能力。O版目前仅有企业版。
PolarDB PostgreSQL版(兼容Oracle)提供全面的Oracle语法兼容性,采用Share-Everything架构,与Oracle保持一致文件组织架构与多版本并发控制,提供常用Oracle语法支持及Oracle常用特性支持以及OCI原生接口,全面支持助力一键从Oracle迁移上云。PolarDB-O兼容了丰富的表分区功能包括常用的RANGE分区、INTERVAL分区、分区SPLIT和MERGE、分区模版等,基于表分区的全局索引可以极大的提升用户的查询性能。
PolarDB-O有两个大版本:1.0和2.0。2.0版本对PostgreSQL在分布式负载前提下的高并发、高写入负载、并行查询和逻辑复制等方面的性能相比于1.0版本有了进一步提升。2.0高度兼容Oracle语法,支持Oracle常见语法特性以及分区表、事务能力、PL/SQL、包、异构连接等重要功能,并且进一步提升了高并发、高写入负载、并行查询和逻辑复制等方面的性能。1.0 兼容性说明、2.0 兼容性说明 1.0的兼容性及常用使用说明如下:
JDBC(Java Database Connectivity)为Java应用程序提供了访问数据库的编程接口。PolarDB PostgreSQL版(兼容Oracle)数据库的JDBC是基于开源的PostgreSQL JDBC开发而来,使用PostgreSQL本地网络协议进行通信,允许Java程序使用标准的、独立于数据库的Java代码连接数据库。下载地址:JDBC驱动(目前版本42.x)
可以通过如下命令将PolarDB的JDBC驱动包安装至本地仓库。
mvn install:install-file -DgroupId=com.aliyun -DartifactId=<安装的Jar包名> -Dversion=1.1.2 -Dpackaging=jar -Dfile=/usr/local/polardb/share/java/<安装的Jar包名.jar>
在Maven的pom.xml文件中添加如下依赖(以42.5.4.0.6为例)。
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>polardb-jdbc18</artifactId>
<version>42.5.4.0.6</version>
</dependency以下功能都通过一个连接参数配置,支持的参数如下表所示。所有的新增参数的生效范围都控制为连接级别,随Connection的生命周期生效。
| 参数名 | 说明 |
|---|---|
| autoCommit | 开启或关闭参数形式的自动提交。取值如下: |
- true(默认):开启参数形式的自动提交。
- false:关闭参数形式的自动提交。 | | autoCommitSpecCompliant | 是否允许自动提交下继续调用commit/rollback方法。取值如下:
- true(默认):允许自动提交下继续调用commit/rollback方法。
- false:不允许自动提交下继续调用commit/rollback方法。 | | blobAsBytea | 是否支持Oracle兼容的BLOB。取值如下:
- true(默认):支持Oracle兼容的BLOB。
- false:不支持Oracle兼容的BLOB。
说明:Oracle语法兼容1.0版本默认值为false | | clobAsText | 是否支持Oracle兼容的CLOB。取值如下:
- true(默认):支持Oracle兼容的CLOB。
- false:不支持Oracle兼容的CLOB。
说明:Oracle语法兼容1.0版本默认值为false | | collectWarning | 是否收集告警(防止内存溢出)。取值如下:
- true(默认):收集告警。
- false:不收集告警。 | | defaultPolarMaxFetchSize | 配合MaxFetchSize实现结果集条数控制,默认值为0。 | | extraFloatDigits | 小数长度。 | | forceDriverType | 强制驱动按照某一种方案去解析。取值为pg、ora、ora11和ora14。 | | mapDateToTimestamp | 是否支持将Date类型转为Timestamp。取值如下:
- true(默认):支持将Date类型转为Timestamp。
- false:不支持将Date类型转为Timestamp。 | | namedParam | 是否支持通过**:xxx**绑定参数。取值如下:
- true:支持通过**:xxx**绑定参数。
- false(默认):不支持通过**:xxx**绑定参数。 | | oracleCase | 是否返回列名、表名的大写。取值如下:
- false(默认):不对返回的列名、表名进行转换。
- true:返回的列名、表名直接全部转换成大写。
- strict:返回的列名、表名在字母全部都是小写的情况下转换成大写。 | | resetNlsFormat | 是否支持将date/timestamp/timestamptz类型默认按照标准格式去识别。取值如下:
- true(默认):支持将date/timestamp/timestamptz类型默认按照标准格式去识别。
- false:不支持将date/timestamp/timestamptz类型默认按照标准格式去识别。 | | unnamedProc | 是否支持匿名块绑定参数功能。取值如下:
- true(默认):支持匿名块绑定参数功能。
- false:不支持匿名块绑定参数功能。 |
为了同时支持Oracle语法兼容1.0和Oracle语法兼容2.0两个版本,PolarDB提供了带有路由功能的JDBC。即在使用过程中,驱动通过连接数据库的类型自动识别,从而选择对应的驱动。 具体的选择方式如下表所示。
| 动态连接头 | 数据库内核版本 | 连接 |
|---|---|---|
| jdbc:postgresql: | 兼容PostgreSQL 11 | 拒绝 |
| 兼容PostgreSQL 14 | 拒绝 | |
| Oracle语法兼容1.0 | 连接,Oracle语法兼容1.0模式 | |
| Oracle语法兼容2.0 | 连接,Oracle语法兼容2.0模式 | |
| jdbc:polardb: | 兼容PostgreSQL 11 | 连接,兼容PostgreSQL模式 |
| 兼容PostgreSQL 14 | 连接,兼容PostgreSQL模式 | |
| Oracle语法兼容1.0 | 连接,Oracle语法兼容1.0模式 | |
| Oracle语法兼容2.0 | 连接,Oracle语法兼容2.0模式 | |
| jdbc:polardb1: | Oracle语法兼容1.0 | 连接,Oracle语法兼容1.0模式 |
| 其他 | 拒绝 | |
| jdbc:polardb2: | Oracle语法兼容2.0 | 连接,Oracle语法兼容2.0模式 |
| 其他 | 拒绝 |
说明
其中,jdbc:postgresql:和jdbc:polardb:属于动态连接头,带有数据库自动路由功能。只使用java.sql中的JDBC标准对象,可以实现两个版本的JDBC自动切换。 而jdbc:polardb1:和jdbc:polardb2:属于静态连接头,静态连接头会唯一指定驱动的模式,相比于动态连接头效率更高,但是不具备路由的功能。
NOTE
以下场景可能会引发Oracle语法兼容1.0和Oracle语法兼容2.0两个版本JDBC无法自动切换,需要根据实际场景修改业务代码解决。
- 不通过Driver而是手动实例化new PgConnection。
- 直接import使用了com.aliyun.polardb中的对象。
- Date类型:64位Date类型的支持。内核支持了64位的Date,数据表示格式与Oracle相同,带有时分秒信息,对应驱动可以以Timestamp的方式去处理该Date。将所有的Date类型(Types.DATE或者DATEOID)映射成Timestamp类型,驱动将Date视为Timestamp进行处理。
- Interval类型:支持Oracle模式的Interval输入。PG社区的驱动不支持例如**+12 12:03:12.111**形式的Interval输入,由于目前Oracle模式下该形式是标准输出,所以PolarDB-O支持这种形式的输出。
- Number类型:支持Number的GET行为。Java.sql的标准实现中没有getNumber相关的函数,只有getInt等函数。如果一个函数的参数类型是Number,允许使用getInt、setInt、RegisterParam等接口将参数以Int形式传递。
- Blob类型:Blob处理为Bytea,Clob处理为Text。针对Java.sql.Blob和Java.sql.Clob接口的实现。内核已经为Blob、Clob添加了映射,在Java层面也可以按照Bytea、Text的方式去处理。主类实现了getBytes、setBytes、position、getBinaryStream等方法。
- 支持不带$$符号的存储过程。支持在创建FUNCTION/PROCEDURE等过程时省略**$$符号,并支持在语法解析时截断/**字符。
- 支持冒号变量名作为参数。支持使用**:xxx这种方式传递参数,其中xxx**为冒号开头的变量名。
- 支持匿名块绑定参数。
- 支持屏蔽PLSQL的警告信息。防止循环中存储过多的警告信息导致内存超限。
以下命令加载JDBC驱动:
Class.forName("com.aliyun.polardb.Driver");
Class.forName("com.aliyun.polardb2.Driver");**说明:**如果是通过项目导入的方式导入JDBC,以上驱动都会自动注册完成,不需要额外注册。例如,使用Maven Install。
| 参数 | 示例 | 说明 |
|---|---|---|
| URL前缀 | jdbc:polardb:// | 连接PolarDB的URL统一使用**jdbc:polardb://**作为前缀。 |
| 连接地址 | pc-***.o.polardb.rds.aliyuncs.com | PolarDB集群的连接地址,如何查看连接地址参见查看或申请连接地址。 |
| 端口 | 1521 | PolarDB集群的端口,默认为1521。 |
| 数据库 | polardb_test | 需要连接的数据库名。 |
| 用户名 | test | PolarDB集群的用户名。 |
| 密码 | Pw123456 | PolarDB集群用户名对应的密码。 |
访问数据库执行查询时,需要创建一个Statement、PreparedStatment或者CallableStatement对象。使用PreparedStatment示例如下:
PreparedStatement st = conn.prepareStatement("select id, name from foo where id > ?");
st.setInt(1, 10);
resultSet = st.executeQuery();
while (resultSet.next()) {
System.out.println("id:" + resultSet.getInt(1));
System.out.println("name:" + resultSet.getString(2));
}访问数据库存储过程时,如果要使用带有OUT参数的存储过程,需要创建CallableStatement对象。并使用 registerOutParameter,使用示例如下:
jdbc:polardb://pc-***.o.polardb.rds.aliyuncs.com:1521/polardb_test?user=test&password=Pw123456
PreparedStatement st = conn.prepareStatement("select id, name from foo where id > ?");
st.setInt(1, 10);
resultSet = st.executeQuery();
while (resultSet.next()) {
System.out.println("id:" + resultSet.getInt(1));
System.out.println("name:" + resultSet.getString(2));
}String sql = "CREATE or replace PROCEDURE test_in_out_procedure(a IN integer, b INOUT integer, c OUT integer)\n" +
"AS $$\n" +
"BEGIN\n" +
" c = a + b;\n" +
" b = a;\n" +
"return;\n" +
"END;\n" +
"$$;";
conn.createStatement().execute(sql);
CallableStatement stmt = conn.prepareCall("{call test_in_out_procedure(?,?,?)}");
stmt.setInt(1, 1);
stmt.setInt(2, 2);
stmt.registerOutParameter(2, Types.INTEGER);
stmt.registerOutParameter(3, Types.INTEGER);
stmt.execute();
System.out.println("get $2 = " + stmt.getInt(2));
System.out.println("get $3 = " + stmt.getInt(3));
// OUTPUT:
// get $2 = 1
// get $3 = 3如果工程使用Hibernate连接数据库,在Hibernate配置文件hibernate.cfg.xml中配置PolarDB数据库的驱动类和方言。 **说明:**Hibernate需要为3.6及以上版本才支持PostgresPlusDialect方言。
Druid 1.1.24之前的版本,需要显式设置driver name和dbtype参数,如下所示:
dataSource.setDriverClassName("com.aliyun.polardb2.Driver");
dataSource.setDbType("postgresql");**说明:**Druid 1.1.24之前版本没有适配PolarDB,因此dbtype需要设置为postgresql。如果需要在Druid连接池中对数据库密码进行加密,参见数据库密码加密。(与Seata的druid版本适配没问题)
PolarDB-O兼容版在开源PostgreSQL的基础上实现了众多兼容性相关的特性,有些特性需要驱动层配合实现,因此,推荐使用PolarDB的JDBC驱动。相关驱动可以在官网驱动下载页面下载。
按照官网描述,JDBC驱动需要在官网下载jar包,对于Maven工程需要手动安装该jar包至本地仓库使用,目前仅支持官网下载JDBC驱动包一种方式。
通过运行java -jar 驱动名来查看版本号。
PolarDB PostgreSQL版(兼容Oracle)的JDBC驱动支持在URL中配置多个IP和端口,示例如下:
jdbc:poalardb://1.2.XX.XX:5432,2.3.XX.XX:5432/postgres**说明:**配置多个IP后,创建连接时会依次尝试通过这些IP创建连接,若都不能创建连接,则连接创建失败。每个IP尝试创建连接的超时时间默认为10s,即connectTimeout,若要修改超时时间,可在连接串中添加该参数进行设置。
如果是java 1.8之前的JDK,使用Types.REF;如果是java 1.8及其之后的版本,可以使用Types.REF_CURSOR。
可以在JDBC连接串中添加参数oracleCase=true,该参数会将返回的列名默认转换为大写。该特性可能需要在后续与Seata的EscapeHandler功能做跟进。 示例如下:
jdbc:poalardb://1.2.XX.XX:5432,2.3.XX.XX:5432/postgres?oracleCase=true官网 PolarDB - 企业版 文档大全 PolarDB-X 开源版 Github仓库 PolarDB-PG 开源版 Github仓库 PolarDB-PG & PoalrDB-MySQL 企业版 PolarDB-X 企业版 媒体 PolarDB-X知乎公众号 PolarDB微信公众号 PolarDB的架构 PolarDB-X 简介 PolarDB-X:云原生分布式数据库 PolarDB PostgreSQL 架构原理 PolarDB-X 2.0 的ACID实现(什么是MDL? 什么是双版本元数据? 什么是同城三机房和三地五中心?PolarDB-X的HA如何实现?) 《PolarDB-X Online Schema Change》 《PolarDB-X:让“Online DDL”更Online》 《PolarDB-X 一致性共识协议 —— X-Paxos》 《PolarDB-X 存储架构之“基于Paxos的最佳生产实践”》 PolarDB-X 2.0 的分布式事务实现(XA和2PC有什么区别和联系?什么是TSO? 什么是HLC? 什么是MVCC? ) 《无处不在的 MySQL XA 事务》 《InnoDB事务 - 从原理到实现》 《PolarDB-X 强一致分布式事务原理》 《分布式数据库中的一致性与时间戳》 《PolarDB-X 全局时间戳服务的设计》 《PolarDB-X 分布式事务的实现(一)》 《PolarDB-X 分布式事务的实现(二)InnoDB CTS 扩展》 《PolarDB-X 分布式事务的实现(三):异步提交优化》 《PolarDB-X 分布式事务的实现(四):跨地域事务》