![]()
JDBC is so much simpler with rxjava2-jdbc.
For Rxjava 3.x see rxjava3-jdbc.
Status: published to Maven Central
Use this maven dependency:
<dependency>
<groupId>com.github.davidmoten</groupId>
<artifactId>rxjava2-jdbc</artifactId>
<version>VERSION_HERE</version>
</dependency>If you want to use the built-in test database then add the Apache Derby dependency (otherwise you’ll need the jdbc dependency for the database you want to connect to):
<dependency>
<groupId>org.apache.derby</groupId>
<artifactId>derby</artifactId>
<version>10.14.2.0</version>
</dependency>To start things off you need a Database instance. Given the jdbc url of your database you can create a Database object like this:
Database db = Database.from(url, maxPoolSize);If you want to have a play with a built-in test database then do this:
Database db = Database.test(maxPoolSize);To use the built-in test database you will need the Apache Derby dependency:
<dependency>
<groupId>org.apache.derby</groupId>
<artifactId>derby</artifactId>
<version>10.14.2.0</version>
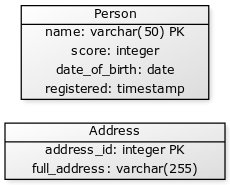
</dependency>The test database has a few tables (see script) including Person and Address with three rows in Person and two rows in Address:
Each time you call Database.test(maxPoolSize) you will have a fresh new database to play with that is loaded with data as described above.
Let’s use a Database instance to perform a select query on the Person table and write the names to the console:
Database db = Database.test();
db.select("select name from person")
.getAs(String.class)
.blockingForEach(System.out::println);Output is
FRED
JOSEPH
MARMADUKENote the use of blockingForEach. This is only for demonstration purposes. When a query is executed it is executed asynchronously on a scheduler that you can specify if desired. The default scheduler is:
Schedulers.from(Executors.newFixedThreadPool(maxPoolSize));While you are processing reactively you should avoid blocking calls but domain boundaries sometimes force this to happen (e.g. accumulate the results and return them as xml over the network from a web service call). Bear in mind also that if you are worried about the complexities of debugging RxJava programs then you might wish to make brief limited forays into reactive code. That’s completely fine too. What you lose in efficiency you may gain in simplicity.
The query flowables returned by the Database all run asynchronously. This is required because of the use of non-blocking connection pools. When a connection is returned to the pool and then checked-out by another query that checkout must occur on a different thread so that stack overflow does not occur. See the Non-blocking connection pools section for more details.
RxJava2 does not support streams of nulls. If you want to represent nulls in your stream then use java.util.Optional.
In the special case where a single nullable column is being returned and mapped to a class via getAs you should instead use getAsOptional:
Database.test()
.select("select date_of_birth from person where name='FRED'")
.getAsOptional(Instant.class)
.blockingForEach(System.out::println);Output:
Optional.emptyNulls will happily map to Tuples (see the next section) when you have two or more columns.
You can specify an explicit null parameter like this:
Database.test()
.update("update person set date_of_birth = ?")
.parameter(null)
.counts()
.blockingForEach(System.out::println);or using named parameters:
Database.test()
.update("update person set date_of_birth = :dob")
.parameter(Parameter.create("dob", null))
.counts()
.blockingForEach(System.out::println);If you use a stream of parameters then you have to be more careful (nulls are not allowed in RxJava streams):\
Database.test()
.update("update person set date_of_birth = ?")
.parameterStream(Flowable.just(Parameter.NULL))
.counts()
.blockingForEach(System.out::println);When you specify more types in the getAs method they are matched to the columns in the returned result set from the query and combined into a Tuple instance. Here’s an example that returns Tuple2:
Database db = Database.test();
db.select("select name, score from person")
.getAs(String.class, Integer.class)
.blockingForEach(System.out::println);Output
Tuple2 [value1=FRED, value2=21]
Tuple2 [value1=JOSEPH, value2=34]
Tuple2 [value1=MARMADUKE, value2=25]Tuples are defined from Tuple2 to Tuple7 and for above that to TupleN.
You can map each row of the JDBC ResultSet to your own object using the get method:
Database db = Database.test();
db.select("select name, score from person order by name")
.get(rs -> new Person(rs.getString("name"), rs.getInt("score")))
.doOnNext(System.out::println) //
.subscribe();By the way it is definitely not a good idea to hang on to a bunch of rs objects as their state will always be that of the latest read row. For this reason you immediately map it to something else either by manually mapping or automapping.
To map the result set values to an interface, first declare an interface:
interface Person {
@Column
String name();
@Column
int score();
}In the query use the autoMap method and let’s use some of the built-in testing methods of RxJava2 to confirm we got what we expected:
Database db = Database.test();
db.select("select name, score from person order by name")
.autoMap(Person.class)
.doOnNext(System.out::println)
.firstOrError()
.map(Person::score)
.test()
.assertValue(21)
.assertComplete();If your interface method name does not exactly match the column name (underscores and case are ignored) then you can add more detail to the Column annotation:
interface Person {
@Column("name")
String fullName();
@Column("score")
int examScore();
}You can also refer to the 1-based position of the column in the result set instead of its name:
interface Person {
@Index(1)
String fullName();
@Index(2)
int examScore();
}In fact, you can mix use of named columns and indexed columns in automapped interfaces.
If you don’t configure things correctly these exceptions may be emitted and include extra information in the error message about the affected automap interface:
-
AnnotationsNotFoundException -
ColumnIndexOutOfRangeException -
ColumnNotFoundException -
ClassCastException -
AutomappedInterfaceInaccessibleException
The toString() method is implemented for automapped objects. For example the toString method for a Person object produces something like:
Person[name=FRED, score=21]The equals and hashCode methods on automapped objects have been implemented based on method value comparisons. For example
-
Person[name=FRED, score=21]is equal toPerson[name=FRED, score=21] -
Person[name=FRED, score=21]is not equal toPerson[name=FRED, score=22] -
Person[name=FRED, score=21]is not equal toPerson2[name=FRED, score=21]
Note that if you try to compare an automapped object with a custom implementation of the automapped interface then the custom implementation must implement equals/hashCode in the same way. In short, avoid doing that!
-
Java 8 - Calling a default method on an automapped interface is supported provided the interface is public and you use the default SecurityManager.
-
Java 9 - not supported yet (TODO)
The automapped interface can be annotated with the select query:
@Query("select name, score from person order by name")
interface Person {
@Column
String name();
@Column
int score();
}To use the annotated interface:
Database
.test()
.select(Person.class)
.get()
.map(Person::name)
.blockingForEach(System.out::println);Output:
FRED
JOSEPH
MARMADUKEIn fact the .map is not required if you use a different overload of get:
Database
.test()
.select(Person.class)
.get(Person::name)
.blockingForEach(System.out::println);See example. Below is how you annotate an interface in Kotlin for automap:
@Query("select name from person order by name")
interface Person {
@Column("name")
fun nm() : String
}The automatic mappings below of objects are used in the autoMap()getAs()java.sql.Datejava.sql.Timejava.sql.Timestampjava.util.Datejava.sql.Datejava.sql.Timejava.sql.Timestampjava.lang.Longjava.sql.Datejava.sql.Timejava.sql.Timestampjava.time.Instantjava.sql.Datejava.sql.Timejava.sql.Timestampjava.time.ZonedDateTimejava.sql.Blobjava.io.InputStreambyte[]java.sql.Clobjava.io.ReaderStringjava.math.BigIntegerLongIntegerDecimalFloatShortjava.math.BigDecimaljava.math.BigDecimalLongIntegerDecimalFloatShortjava.math.BigInteger
Parameters are passed to individual queries but can also be used as a streaming source to prompt the query to be run many times.
Parameters can be named or anonymous. Named parameters are not supported natively by the JDBC specification but rxjava2-jdbc does support them.
This is sql with a named parameter:
select name from person where name=:nameThis is sql with an anonymous parameter:
select name from person where name=?In the example below the query is first run with name='FRED' and then name=JOSEPH. Each query returns one result which is printed to the console.
Database.test()
.select("select score from person where name=?")
.parameters("FRED", "JOSEPH")
.getAs(Integer.class)
.blockingForEach(System.out::println);Output is:
21
34You can specify a stream as the source of parameters:
Database.test()
.select("select score from person where name=?")
.parameterStream(Flowable.just("FRED","JOSEPH").repeat())
.getAs(Integer.class)
.take(3)
.blockingForEach(System.out::println);Output is:
21
34
21Database.test()
.select("select score from person where name=?")
.parameterStream(Flowable.just("FRED","JOSEPH"))
.parameters("FRED", "JOSEPH")
.getAs(Integer.class)
.blockingForEach(System.out::println);Output is:
21
34
21
34If there is more than one parameter per query:
Database.test()
.select("select score from person where name=? and score=?")
.parameterStream(Flowable.just("FRED", 21, "JOSEPH", 34).repeat())
.getAs(Integer.class)
.take(3)
.blockingForEach(System.out::println);or you can group the parameters into lists (each list corresponds to one query) yourself:
Database.test()
.select("select score from person where name=? and score=?")
.parameterListStream(Flowable.just(Arrays.asList("FRED", 21), Arrays.asList("JOSEPH", 34)).repeat())
.getAs(Integer.class)
.take(3)
.blockingForEach(System.out::println);If the query has no parameters you can use the parameters to drive the number of query calls (the parameter values themselves are ignored):
Database.test()
.select("select count(*) from person")
.parameters("a", "b", "c")
.getAs(Integer.class)
.blockingForEach(System.out::println);Output:
3
3
3Collection parameters are useful for supplying to IN clauses. For example:
Database.test()
.select("select score from person where name in (?) order by score")
.parameter(Sets.newHashSet("FRED", "JOSEPH"))
.getAs(Integer.class)
.blockingForEach(System.out::println);or with named parameters:
Database.test()
.update("update person set score=0 where name in (:names)")
.parameter("names", Lists.newArrayList("FRED", "JOSEPH"))
.counts()
.blockingForEach(System.out::println);You need to pass an implementation of java.util.Collection to one of these parameters (for example java.util.List or java.util.Set).
Under the covers rxjava2-jdbc does not use PreparedStatement.setArray because of the patchy support for this method (not supported by DB2 or MySQL for instance) and the extra requirement of specifying a column type.
Note that databases normally have a limit on the number of parameters in a statement (or indeed the size of array that can be passed in setArray). For Oracle it’s O(1000), H2 it is O(20000).
select and update statements are supported as of 0.1-RC23. If you need callable statement support raise an issue.
A new exciting feature of rxjava2-jdbc is the availability of non-blocking connection pools.
In normal non-reactive database programming a couple of different threads (started by servlet calls for instance) will race for the next available connection from a pool of database connections. If no unused connection remains in the pool then the standard non-reactive approach is to block the thread until a connection becomes available.
Blocking a thread is a resource issue as each blocked thread holds onto ~0.5MB of stack and may incur context switch and memory-access delays (adds latency to thread processing) when being switched to. For example 100 blocked threads hold onto ~50MB of memory (outside of java heap).
rxjava-jdbc2 uses non-blocking JDBC connection pools by default (but is configurable to use whatever you want). What happens in practice is that for each query a subscription is made to a MemberSingle instance controlled by the NonBlockingConnectionPool object that emits connections when available to its subscribers (first in best dressed). So the definition of the processing of that query is stored on a queue to be started when a connection is available. Adding the Flowable definition of your query to the queue can be quite efficient in terms of memory use compared to the memory costs of thread per query. For example a heap dump of 1000 queued simple select statements from the person table in the test database used 429K of heap. That is 429 bytes per query.
The simplest way of creating a Database instance with a non-blocking connection pool is:
Database db = Database.from(url, maxPoolSize);If you want to play with the in-memory built-in test database (requires Apache Derby dependency) then:
Database db = Database.test(maxPoolSize);If you want more control over the behaviour of the non-blocking connection pool:
Database db = Database
.nonBlocking()
// the jdbc url of the connections to be placed in the pool
.url(url)
// an unused connection will be closed after thirty minutes
.maxIdleTime(30, TimeUnit.MINUTES)
// connections are checked for healthiness on checkout if the connection
// has been idle for at least 5 seconds
.healthCheck(DatabaseType.ORACLE)
.idleTimeBeforeHealthCheck(5, TimeUnit.SECONDS)
// if a connection fails creation then retry after 30 seconds
.createRetryInterval(30, TimeUnit.SECONDS)
// the maximum number of connections in the pool
.maxPoolSize(3)
.build();Note that the health check varies from database to database. The following databases are directly supported with DatabaseType instances:
-
DB2
-
Derby
-
HSQLDB
-
H2
-
Informix
-
MySQL
-
Oracle
-
Postgres
-
Microsoft SQL Server
-
SQLite
Lets create a database with a non-blocking connection pool of size 1 only and demonstrate what happens when two queries run concurrently. We use the in-built test database for this one so you can copy and paste this code to your ide and it will run (in a main method or unit test say):
// create database with non-blocking connection pool
// of size 1
Database db = Database.test(1);
// start a slow query
db.select("select score from person where name=?")
.parameter("FRED")
.getAs(Integer.class)
// slow things down by sleeping
.doOnNext(x -> Thread.sleep(1000))
// run in background thread
.subscribeOn(Schedulers.io())
.subscribe();
// ensure that query starts
Thread.sleep(100);
// query again while first query running
db.select("select score from person where name=?")
.parameter("FRED")
.getAs(Integer.class)
.doOnNext(x -> System.out.println("emitted on " + Thread.currentThread().getName()))
.subscribe();
System.out.println("second query submitted");
// wait for stuff to happen asynchronously
Thread.sleep(5000);The output of this is
second query submitted
emitted on RxCachedThreadScheduler-1What has happened is that
-
the second query registers itself as something that will run as soon as a connection is released (by the first query).
-
no blocking occurs and we immediately see the first line of output
-
the second query runs after the first
-
in fact we see that the second query runs on the same Thread as the first query as a direct consequence of non-blocking design
Blobs and Clobs are straightforward to handle.
Here’s how to insert a String value into a Clob (document column below is of type CLOB
String document = ...
Flowable<Integer> count = db
.update("insert into person_clob(name,document) values(?,?)")
.parameters("FRED", document)
.count();If your document is nullable then you should use Database.clob(document):
String document = ...
Flowable<Integer> count = db
.update("insert into person_clob(name,document) values(?,?)")
.parameters("FRED", Database.clob(document))
.count();Using a java.io.Reader
Reader reader = ...;
Flowable<Integer> count = db
.update("insert into person_clob(name,document) values(?,?)")
.parameters("FRED", reader)
.count();Flowable<Integer> count = db
.update("insert into person_clob(name,document) values(?,?)")
.parameters("FRED", Database.NULL_CLOB)
.count();or
Flowable<Integer> count = db
.update("insert into person_clob(name,document) values(?,?)")
.parameters("FRED", Database.clob(null))
.count();Flowable<String> document =
db.select("select document from person_clob")
.getAs(String.class);or
Flowable<Reader> document =
db.select("select document from person_clob")
.getAs(Reader.class);For the special case where you want to return one value from a select statement and that value is a nullable CLOB then use getAsOptional:
db.select("select document from person_clob where name='FRED'")
.getAsOptional(String.class)Similarly for Blobs (document column below is of type BLOB
byte[] bytes = ...
Flowable<Integer> count = db
.update("insert into person_blob(name,document) values(?,?)")
.parameters("FRED", Database.blob(bytes))
.count();This requires either a special call (parameterBlob(String)
Flowable<Integer> count = db
.update("insert into person_blob(name,document) values(?,?)")
.parameters("FRED", Database.NULL_BLOB)
.count();or
Flowable<Integer> count = db
.update("insert into person_clob(name,document) values(?,?)")
.parameters("FRED", Database.blob(null))
.count();If you insert into a table that say in h2 is of type auto_increment then you don’t need to specify a value but you may want to know what value was inserted in the generated key field.
Given a table like this
create table note(
id bigint auto_increment primary key,
text varchar(255)
)This code inserts two rows into the note table and returns the two generated keys:
Flowable<Integer> keys =
db.update("insert into note(text) values(?)")
.parameters("hello", "there")
.returnGeneratedKeys()
.getAs(Integer.class);The returnGeneratedKeys method also supports returning multiple keys per row so the builder offers methods just like select to do explicit mapping or auto mapping.
Transactions are a critical feature of relational databases.
When we’re talking RxJava we need to consider the behaviour of individual JDBC objects when called by different threads, possibly concurrently. The approach taken by rxjava2-jdbc outside of a transaction safely uses Connection pools (in a non-blocking way). Inside a transaction we must make all calls to the database using the same Connection object so the behaviour of that Connection when called from different threads is important. Some JDBC drivers provide thread-safety on JDBC objects by synchronizing every call.
The safest approach with transactions is to perform all db interaction synchronously. Asynchronous processing within transactions was problematic in rxjava-jdbc because ThreadLocal was used to hold the Connection. Asynchronous processing with transactions is possible with rxjava2-jdbc but should be handled with care given that your JDBC driver may block or indeed suffer from race conditions that most users don’t encounter.
Let’s look at some examples. The first example uses a transaction across two select statement calls:
Database.test()
.select("select score from person where name=?")
.parameters("FRED", "JOSEPH")
.transacted()
.getAs(Integer.class)
.blockingForEach(tx ->
System.out.println(tx.isComplete() ? "complete" : tx.value()));Output:
21
34
completeNote that the commit/rollback of the transaction happens automatically.
What we see above is that each emission from the select statement is wrapped with a Tx object including the terminal event (error or complete). This is so you can for instance perform an action using the same transaction.
Let’s see another example that uses the Tx object to update the database. We are going to do something a bit laborious that would normally be done in one update statement (update person set score = -1) just to demonstrate usage:
Database.test()
.select("select name from person")
// don't emit a Tx completed event
.transactedValuesOnly()
.getAs(String.class)
.flatMap(tx -> tx
.update("update person set score=-1 where name=:name")
.parameter("name", tx.value())
// don't wrap value in Tx object
.valuesOnly()
.counts())
.toList()
.blockingForEach(System.out::println);Output:
[1, 1, 1]Callable statement support is a major addition to the code base as of 0.1-RC23.
Callable support is present only outside of transactions (transaction support coming later). If you’re keen for it, raise an issue. The primary impediment is the duplication of a bunch of chained builders for the transacted case.
For example:
Flowable<Tuple2<Integer,Integer>> tuples =
db.call("call in1out2(?,?,?)")
.in()
.out(Type.INTEGER, Integer.class)
.out(Type.INTEGER, Integer.class)
.input(0, 10, 20);Note above that each question mark in the call statement correponds in order with a call to in() or out(…). Once all parameters have been defined then the input(0, 10, 20) call drives the running of the query with that input. The output Flowable is strongly typed according to the out parameters specified.
When you start specifying output ResultSet s from the call then you lose output parameter strong typing but gain ResultSet mapped strong typing as per normal select statements in rxjava2-jdbc.
Here’s an example for one in parameter and two output ResultSet s with autoMap. You can of course use getAs instead (or get):
Flowable<String> namePairs =
db
.call("call in1out0rs2(?)")
.in()
.autoMap(Person2.class)
.autoMap(Person2.class)
.input(0, 10, 20)
.flatMap(x ->
x.results1()
.zipWith(x.results2(), (y, z) -> y.name() + z.name()));The above example is pretty nifty in that we can zip the two result sets resulting from the call and of course the whole thing was easy to define (as opposed to normal JDBC).
You just saw autoMap used to handle an output ResultSet but getAs works too:
Flowable<String> namePairs =
db
.call("call in1out0rs2(?)")
.in()
.getAs(String.class, Integer.class)
.getAs(String.class, Integer.class
.input(0, 10, 20)
.flatMap(x ->
x.results1()
.zipWith(x.results2(), (y, z) -> y._1() + z._1()));You can explore more examples of this in [DatabaseTest.java](rxjava2-jdbc/src/test/java/org/davidmoten/rx/jdbc/DatabaseTest.java). Search for .call.
A few nifty things in JDBC may not yet directly supported by rxjava2-jdbc but you can get acccess to the underlying Connection s from the Database object by using Database.apply or Database.member().
Here’s an example where you want to return something from a Connection (say you called a stored procedure and returned an integer):
Database db = ...
Single<Integer> count =
db.apply(
con -> {
//do whatever you want with the connection
// just don't close it!
return con.getHoldability();
});If you don’t want to return something then use a different overload of apply:
Completable c =
db.apply(con -> {
//do whatever you want with the connection
});Here are lower level versions of the above examples where you take on the responsibility of returning the connection to the pool.
Database db = ...
Single<Integer> count = db.member()
.map(member -> {
Connection con = member.value();
try {
//do whatever you want with the connection
return count;
} finally {
// don't close the connection, just hand it back to the pool
// and don't use this member again!
member.checkin();
});and
Completable completable = db.member()
.doOnSuccess(member -> {
Connection con = member.value();
try {
//do whatever you want with the connection
} finally {
// don't close the connection, just hand it back to the pool
// and don't use this member again!
member.checkin();
}).ignoreElements();Logging is handled by slf4j which bridges to the logging framework of your choice. Add the dependency for your logging framework as a maven dependency and you are sorted. See the test scoped log4j example in rxjava2-jdbc/pom.xml.