Add MoSLoRA (EMNLP 2024) #2294
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,33 @@ | ||
| <!--Copyright 2023 The HuggingFace Team. All rights reserved. | ||
|
|
||
| Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with | ||
| the License. You may obtain a copy of the License at | ||
|
|
||
| http://www.apache.org/licenses/LICENSE-2.0 | ||
|
|
||
| Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on | ||
| an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the | ||
| specific language governing permissions and limitations under the License. | ||
|
|
||
| ⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be | ||
| rendered properly in your Markdown viewer. | ||
|
|
||
| --> | ||
|
|
||
| # MoSLoRA | ||
|
|
||
| [MoSLoRA](https://huggingface.co/papers/2406.11909) is a PEFT method that introduces a learnable mixer to fuse the information of subspaces of LoRA. MoSLoRA is computationally efficient, easy to implement, and readily applicable to large language, multimodal, and diffusion models. | ||
|
|
||
| The abstract from the paper is: | ||
|
|
||
| *In this paper, we introduce a subspace-inspired Low-Rank Adaptation (LoRA) method, which is computationally efficient, easy to implement, and readily applicable to large language, multimodal, and diffusion models. Initially, we equivalently decompose the weights of LoRA into two subspaces, and find that simply mixing them can enhance performance. To study such a phenomenon, we revisit it through a fine-grained subspace lens, showing that such modification is equivalent to employing a fixed mixer to fuse the subspaces. To be more flexible, we jointly learn the mixer with the original LoRA weights, and term the method Mixture-of-Subspaces LoRA (MoSLoRA). MoSLoRA consistently outperforms LoRA on tasks in different modalities, including commonsense reasoning, visual instruction tuning, and subject-driven text-to-image generation, demonstrating its effectiveness and robustness. Codes are available at https://github.com/wutaiqiang/MoSLoRA{github}.*. | ||
|
|
||
| ## MoSLoraConfig | ||
|
|
||
| [[autodoc]] tuners.moslora.config.MoSLoraConfig | ||
|
|
||
| ## MoSLoraModel | ||
|
|
||
| [[autodoc]] tuners.moslora.model.MoSLoraModel | ||
|
|
||
|
|
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change | ||||
|---|---|---|---|---|---|---|
| @@ -0,0 +1,104 @@ | ||||||
| # Mixture-of-Subspaces in Low-Rank Adaptation | ||||||
|
|
||||||
| 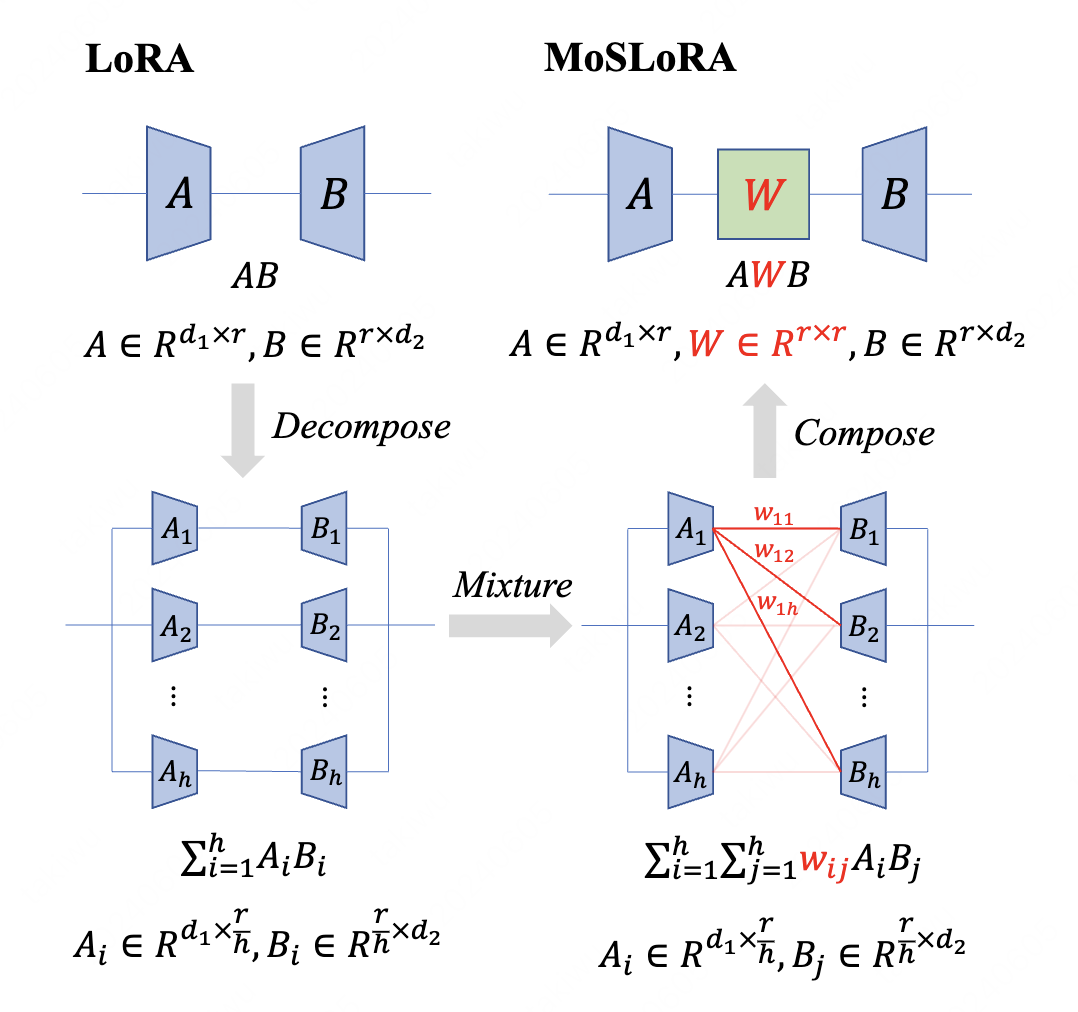 | ||||||
|
|
||||||
|
|
||||||
| ## Introduction | ||||||
| [MoSLoRA](https://arxiv.org/abs/2406.11909) is a novel approach that is computationally efficient, easy to implement, and readily applicable to large language, multimodal, and diffusion models. Initially, we equivalently decompose the weights of LoRA into two subspaces, and find that simply mixing them can enhance performance. To study such a phenomenon, we revisit it through a fine-grained subspace lens, showing that such modification is equivalent to employing a fixed mixer to fuse the subspaces. To be more flexible, we jointly learn the mixer with the original LoRA weights, and term the method Mixture-of-Subspaces LoRA (MoSLoRA). MoSLoRA consistently outperforms LoRA on tasks in different modalities, including commonsense reasoning, visual instruction tuning, and subject-driven text-to-image generation, demonstrating its effectiveness and robustness. | ||||||
|
|
||||||
| ## Quick start | ||||||
| ```python | ||||||
| import torch | ||||||
| from peft import MoSLoraConfig, get_peft_model | ||||||
| from transformers import AutoTokenizer, AutoModelForCausalLM, Trainer | ||||||
| from datasets import load_dataset | ||||||
|
|
||||||
| model = AutoModelForCausalLM.from_pretrained("TinyLlama/TinyLlama-1.1B-Chat-v1.0", device_map="cuda") | ||||||
| tokenizer = AutoTokenizer.from_pretrained("TinyLlama/TinyLlama-1.1B-Chat-v1.0") | ||||||
| dataset = load_dataset("timdettmers/openassistant-guanaco", split="train") | ||||||
| lora_config = MoSLoraConfig( | ||||||
|
There was a problem hiding this comment.
Suggested change
Code below also needs adjusting. |
||||||
| use_moslora=True | ||||||
| ) | ||||||
| peft_model = get_peft_model(model, lora_config) | ||||||
| trainer = transformers.Trainer( | ||||||
| model=peft_model, | ||||||
| train_dataset=dataset, | ||||||
| dataset_text_field="text", | ||||||
| max_seq_length=2048, | ||||||
| tokenizer=tokenizer, | ||||||
| ) | ||||||
| trainer.train() | ||||||
| peft_model.save_pretrained("moslora-tinyllama-1.1") | ||||||
| ``` | ||||||
|
|
||||||
| There is no additional change needed to your standard LoRA procedure, except for replacing __LoraConfig__ with __MoSLoraConfig__ and set `use_moslora=True` option in your configuration. If you set the `use_moslora=False` then the training process would be the same as LoRA. | ||||||
|
|
||||||
|
|
||||||
| Run the finetuning script simply by running: | ||||||
| ```bash | ||||||
| python examples/moslora_finetuning/moslora_finetuning.py --base_model TinyLlama/TinyLlama-1.1B-Chat-v1.0 --data_path timdettmers/openassistant-guanaco | ||||||
| ``` | ||||||
| This 👆🏻 by default will load the model in peft set up with LoRA config. Now if you wanna quickly compare it with MoSLoRA, all you need to do is to input ` --use_moslora` in the command line. So same above example would be 👇🏻; | ||||||
|
|
||||||
| ```bash | ||||||
| python examples/moslora_finetuning/moslora_finetuning.py --base_model TinyLlama/TinyLlama-1.1B-Chat-v1.0 --data_path timdettmers/openassistant-guanaco --use_moslora True | ||||||
| ``` | ||||||
|
|
||||||
| Moreover, you can set use_moslora as `"kai"` for Kaiming Uniform initilization or `"orth"` for orthogonal initilization. | ||||||
|
|
||||||
|
|
||||||
| Similarly, by default the LoRA layers are the attention and MLP layers of LLama model, if you get to choose a different set of layers for LoRA to be applied on, you can simply define it using: | ||||||
| ```bash | ||||||
| python examples/moslora_finetuning/moslora_finetuning.py --lora_target_modules "q_proj,k_proj,v_proj,o_proj" | ||||||
| ``` | ||||||
|
|
||||||
| ### Full example of the script | ||||||
| ```bash | ||||||
| python dora_finetuning.py \ | ||||||
| --base_model "PATH_TO_MODEL" \ | ||||||
| --data_path "PATH_TO_DATASET" \ | ||||||
| --output_dir "PATH_TO_OUTPUT_DIR" \ | ||||||
| --batch_size 1 \ | ||||||
| --num_epochs 3 \ | ||||||
| --learning_rate 3e-4 \ | ||||||
| --cutoff_len 512 \ | ||||||
| --val_set_size 500 \ | ||||||
| --use_moslora "kai" \ | ||||||
| --quantize \ | ||||||
| --eval_step 10 \ | ||||||
| --save_step 100 \ | ||||||
| --device "cuda:0" \ | ||||||
| --lora_r 16 \ | ||||||
| --lora_alpha 32 \ | ||||||
| --lora_dropout 0.05 \ | ||||||
| --lora_target_modules "q_proj,k_proj,v_proj,o_proj" \ | ||||||
| --hub_model_id "YOUR_HF_REPO" \ | ||||||
| --push_to_hub | ||||||
| ``` | ||||||
| ## Use the model on 🤗 | ||||||
| You can load and use the model as any other 🤗 models. | ||||||
| ```python | ||||||
| from transformers import AutoModel | ||||||
| model = AutoModel.from_pretrained("ShirinYamani/huggyllama-llama-7b-finetuned") | ||||||
| ``` | ||||||
|
|
||||||
|
|
||||||
|
|
||||||
| ## Citation | ||||||
| ``` | ||||||
| @inproceedings{wu-etal-2024-mixture-subspaces, | ||||||
| title = "Mixture-of-Subspaces in Low-Rank Adaptation", | ||||||
| author = "Wu, Taiqiang and | ||||||
| Wang, Jiahao and | ||||||
| Zhao, Zhe and | ||||||
| Wong, Ngai", | ||||||
| booktitle = "Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing", | ||||||
| month = nov, | ||||||
| year = "2024", | ||||||
| address = "Miami, Florida, USA", | ||||||
| publisher = "Association for Computational Linguistics", | ||||||
| url = "https://aclanthology.org/2024.emnlp-main.450", | ||||||
| doi = "10.18653/v1/2024.emnlp-main.450", | ||||||
| pages = "7880--7899", | ||||||
| } | ||||||
| ``` | ||||||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,203 @@ | ||
| import os | ||
|
|
||
| import torch | ||
| from datasets import load_dataset | ||
| from transformers import ( | ||
| AutoModelForCausalLM, | ||
| AutoTokenizer, | ||
| BitsAndBytesConfig, | ||
| DataCollatorForLanguageModeling, | ||
| Trainer, | ||
| TrainingArguments, | ||
| ) | ||
|
|
||
| from typing import Literal | ||
|
|
||
| from peft import MoSLoraConfig, get_peft_model, prepare_model_for_kbit_training | ||
|
|
||
|
|
||
| def train_model( | ||
| base_model: str, | ||
| data_path: str, | ||
| output_dir: str, | ||
| batch_size: int, | ||
| num_epochs: int, | ||
| learning_rate: float, | ||
| cutoff_len: int, | ||
| val_set_size: int, | ||
| use_moslora: bool | Literal['kai', 'orth'], | ||
| quantize: bool, | ||
| eval_step: int, | ||
| save_step: int, | ||
| device: str, | ||
| lora_r: int, | ||
| lora_alpha: int, | ||
| lora_dropout: float, | ||
| lora_target_modules: str, | ||
| hub_model_id: str, | ||
| push_to_hub: bool, | ||
| ): | ||
| os.environ["TOKENIZERS_PARALLELISM"] = "false" | ||
| hf_token = os.getenv("HF_TOKEN") | ||
|
|
||
| # Setup device | ||
| device = torch.device(device) | ||
| print(f"Using device: {device}") | ||
|
|
||
| # load tokenizer | ||
| tokenizer = AutoTokenizer.from_pretrained(base_model, token=hf_token) | ||
|
|
||
| # QDoRA (quantized dora): IF YOU WANNA QUANTIZE THE MODEL | ||
| if quantize: | ||
| model = AutoModelForCausalLM.from_pretrained( | ||
| base_model, | ||
| token=hf_token, | ||
| quantization_config=BitsAndBytesConfig( | ||
| load_in_4bit=True, | ||
| bnb_4bit_compute_dtype=( | ||
| torch.bfloat16 if torch.cuda.is_available() and torch.cuda.is_bf16_supported() else torch.float16 | ||
| ), | ||
| bnb_4bit_use_double_quant=True, | ||
| bnb_4bit_quant_type="nf4", | ||
| ), | ||
| ) | ||
| # setup for quantized training | ||
| model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=True) | ||
| else: | ||
| model = AutoModelForCausalLM.from_pretrained(base_model, token=hf_token) | ||
| # LoRa config for the PEFT model | ||
| lora_config = MoSLoraConfig( | ||
| use_moslora=use_moslora, # to use moslora, just pass True or "kai" or "orth" | ||
| r=lora_r, # Rank of matrix | ||
| lora_alpha=lora_alpha, | ||
| target_modules=( | ||
| lora_target_modules.split(",") | ||
| if lora_target_modules | ||
| else ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"] | ||
| ), | ||
| lora_dropout=lora_dropout, | ||
| bias="none", | ||
| ) | ||
|
|
||
| # get the peft model with LoRa config | ||
| model = get_peft_model(model, lora_config) | ||
|
|
||
| model.to(device) # MODEL TO GPU/CUDA | ||
| tokenizer.pad_token = tokenizer.eos_token | ||
|
|
||
| # Load the dataset | ||
| dataset = load_dataset(data_path) | ||
|
|
||
| def tokenize_function(examples): | ||
| inputs = tokenizer(examples["text"], padding="max_length", truncation=True, max_length=cutoff_len) | ||
| inputs["labels"] = inputs["input_ids"].copy() # setting labels for a language modeling task | ||
| return inputs | ||
|
|
||
| # Tokenize the dataset and prepare for training | ||
| tokenized_datasets = dataset.map(tokenize_function, batched=True, remove_columns=dataset["train"].column_names) | ||
|
|
||
| # Data collator to dynamically pad the batched examples | ||
| data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False) | ||
|
|
||
| # Define training arguments | ||
| training_args = TrainingArguments( | ||
| output_dir=output_dir, | ||
| num_train_epochs=num_epochs, | ||
| per_device_train_batch_size=batch_size, | ||
| per_device_eval_batch_size=batch_size, | ||
| warmup_steps=100, | ||
| weight_decay=0.01, | ||
| logging_dir="./logs", | ||
| logging_steps=eval_step, | ||
| save_steps=save_step, | ||
| save_total_limit=2, | ||
| push_to_hub=push_to_hub, | ||
| hub_model_id=hub_model_id, | ||
| gradient_accumulation_steps=16, | ||
| fp16=True, | ||
| learning_rate=learning_rate, | ||
| hub_token=hf_token, | ||
| remove_unused_columns=False, | ||
| ) | ||
|
|
||
| # Clear CUDA cache to free memory | ||
| torch.cuda.empty_cache() | ||
|
|
||
| # Initialize the Trainer | ||
| trainer = Trainer( | ||
| model=model, | ||
| args=training_args, | ||
| train_dataset=tokenized_datasets["train"], | ||
| eval_dataset=tokenized_datasets["test"], | ||
| data_collator=data_collator, | ||
| ) | ||
|
|
||
| # Start model training | ||
| trainer.train() | ||
|
|
||
| # Save and push the trained model and tokenizer | ||
| if push_to_hub: | ||
| # Push the main model to the hub | ||
| trainer.push_to_hub(commit_message="Fine-tuned model") | ||
|
|
||
| # Save the model and tokenizer locally | ||
| model.save_pretrained(output_dir) | ||
| tokenizer.save_pretrained(output_dir) | ||
|
|
||
|
|
||
| if __name__ == "__main__": | ||
| import argparse | ||
|
|
||
| parser = argparse.ArgumentParser(description="Fine-tune TinyLLaMA with MoSLoRA and PEFT") | ||
| parser.add_argument("--base_model", type=str, default="TinyLlama/TinyLlama-1.1B-Chat-v1.0", help="Base model path or name") | ||
| parser.add_argument( | ||
| "--data_path", type=str, default="timdettmers/openassistant-guanaco", help="Dataset path or name" | ||
| ) | ||
| parser.add_argument( | ||
| "--output_dir", type=str, default="path/to/output", help="Output directory for the fine-tuned model" | ||
| ) | ||
| parser.add_argument("--batch_size", type=int, default=1, help="Batch size") | ||
| parser.add_argument("--num_epochs", type=int, default=1, help="Number of training epochs") | ||
| parser.add_argument("--learning_rate", type=float, default=3e-4, help="Learning rate") | ||
| parser.add_argument("--cutoff_len", type=int, default=512, help="Cutoff length for tokenization") | ||
| parser.add_argument("--val_set_size", type=int, default=500, help="Validation set size") | ||
| parser.add_argument("--use_moslora", type=bool | Literal['kai', 'orth'], default=False, help="Apply MoSLoRA") | ||
| parser.add_argument("--quantize", action="store_true", help="Use quantization") | ||
| parser.add_argument("--eval_step", type=int, default=10, help="Evaluation step interval") | ||
| parser.add_argument("--save_step", type=int, default=100, help="Save step interval") | ||
| parser.add_argument("--device", type=str, default="cuda:0", help="Device to use for training") | ||
| parser.add_argument("--lora_r", type=int, default=8, help="LoRA rank") | ||
| parser.add_argument("--lora_alpha", type=int, default=16, help="LoRA alpha") | ||
| parser.add_argument("--lora_dropout", type=float, default=0.05, help="LoRA dropout rate") | ||
| parser.add_argument( | ||
| "--lora_target_modules", type=str, default=None, help="Comma-separated list of target modules for LoRA" | ||
| ) | ||
| parser.add_argument( | ||
| "--hub_model_id", | ||
| type=str, | ||
| default="path/to/repo", | ||
| help="Repository name to push the model on the Hugging Face Hub", | ||
| ) | ||
| parser.add_argument("--push_to_hub", action="store_true", help="Whether to push the model to Hugging Face Hub") | ||
| args = parser.parse_args() | ||
| train_model( | ||
| base_model=args.base_model, | ||
| data_path=args.data_path, | ||
| output_dir=args.output_dir, | ||
| batch_size=args.batch_size, | ||
| num_epochs=args.num_epochs, | ||
| learning_rate=args.learning_rate, | ||
| cutoff_len=args.cutoff_len, | ||
| val_set_size=args.val_set_size, | ||
| use_moslora=args.use_moslora, | ||
| quantize=args.quantize, | ||
| eval_step=args.eval_step, | ||
| save_step=args.save_step, | ||
| device=args.device, | ||
| lora_r=args.lora_r, | ||
| lora_alpha=args.lora_alpha, | ||
| lora_dropout=args.lora_dropout, | ||
| lora_target_modules=args.lora_target_modules, | ||
| hub_model_id=args.hub_model_id, | ||
| push_to_hub=args.push_to_hub, | ||
| ) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Let's reword this, there is no need for having "try to", right?